Technical Overview
Grok AI represents a sophisticated implementation of transformer-based architecture with several distinctive engineering choices that differentiate it from other large language models. This technical analysis examines Grok's architecture, performance characteristics, and implementation details to provide a comprehensive understanding of its capabilities and limitations.
Grok 3 benchmark snapshot (March 2026)
| Benchmark | Grok 3 | GPT-4o | Claude 3.7 |
|---|---|---|---|
| MMLU | 92.7% | 88.7% | 90.8% |
| HumanEval (coding) | 88.4% | 90.2% | 92.1% |
| MATH | 93.8% | 76.6% | 78.2% |
| GPQA (science) | 75.4% | 53.6% | 78.9% |
Architectural Framework
Grok AI is built on an advanced transformer architecture that builds upon fundamental innovations in the field while introducing several architectural refinements:
Core Architectural Design
At its foundation, Grok employs a decoder-only transformer architecture similar to GPT models, utilizing the established self-attention mechanism first introduced in the "Attention is All You Need" paper. However, xAI has implemented several architectural modifications that enhance Grok's capabilities:
- Enhanced Self-Attention Mechanism: Grok's architecture incorporates multi-head attention with what appears to be modified attention patterns that improve its ability to maintain coherence across longer contexts. This likely includes optimized attention routing that allows for more efficient processing of the attention matrix.
- Scaled Residual Connections: The model utilizes enhanced residual connections throughout its layers, with carefully calibrated scaling factors that help maintain signal strength across the deep network. These scaled residuals appear to be particularly important for Grok's reasoning capabilities.
- Normalization Strategy: Grok employs a sophisticated normalization approach, likely utilizing a variant of RMSNorm (Root Mean Square Normalization) instead of the traditional LayerNorm. This normalization strategy provides more stable training dynamics and improved inference efficiency.
- Position Encoding: The model implements an enhanced rotary position encoding (RoPE) system that enables better handling of positional information throughout the network. This improved positional encoding contributes to Grok's ability to maintain coherence across its context window.
- Web Access Integration Layer: A distinctive architectural feature is Grok's dedicated subsystem for integrating with web browsing capabilities. This includes specialized components for query formulation, result processing, and information integration that are tightly coupled with the core language modeling architecture.
The overall architecture represents a sophisticated evolution of the transformer paradigm, with particular emphasis on enhancements that support Grok's real-time information retrieval capabilities.
Model Specifications
While xAI has not publicly disclosed all specifications for Grok, analysis and benchmarking suggest the following technical characteristics:
- Parameter Count: Grok-1 is estimated to contain between 100 billion and 175 billion parameters, placing it in the same general scale class as models like GPT-4, Claude 2, and PaLM 2. Subsequent versions (Grok-1.5, Grok-1.5V) likely maintain similar parameter counts with architectural improvements rather than raw size increases.
- Context Window: Grok maintains a context window of approximately 8,000 tokens, allowing it to process and maintain awareness of relatively long conversations and documents. This context length balances comprehensiveness with computational efficiency.
- Tokenization Approach: The model likely employs a subword tokenization method similar to Byte-Pair Encoding (BPE) or SentencePiece, with a vocabulary size estimated to be between 50,000 and 100,000 tokens. This tokenization strategy provides efficient representation of the language while handling rare words effectively.
- Precision Implementation: Grok likely employs mixed-precision computation for optimal performance, using a combination of FP16/BF16 and FP32 calculations to balance computational efficiency with numerical stability.
- Training Computation: Based on model scale, training Grok would have required approximately 10^23 to 10^24 FLOPS (floating-point operations) of compute, representing a substantial but not unprecedented investment in training resources.
- Inference Optimization: The model appears to implement several inference optimization techniques, including key-value caching, attention optimizations, and potentially quantized inference for production deployment.
These specifications position Grok as a high-capacity model with substantial representational power, though perhaps not at the absolute frontier of model scale compared to the largest reported systems.
Core Components
Grok's architecture consists of several key components that work together to deliver its capabilities:
- Token Embedding System: Transforms input tokens into high-dimensional vector representations while capturing semantic relationships between words and subwords.
- Multi-layer Transformer Stack: The core computation engine, consisting of multiple transformer blocks with self-attention mechanisms, feed-forward networks, and residual connections. Each block progressively refines representations through:
- Multi-head self-attention for capturing relationships between tokens
- Position-wise feed-forward networks for transformation and feature extraction
- Residual connections and normalization layers for stable signal propagation
- Context Management System: Specialized components for maintaining and utilizing conversation history, including:
- Context compression mechanisms
- Attention optimization for efficient processing of long contexts
- Reference resolution subsystems for maintaining coherence
- Web Browsing Subsystem: A distinctive component that enables real-time information access, including:
- Query formulation engine: Transforms user questions into effective search queries
- Content extraction system: Identifies and extracts relevant information from web pages
- Information synthesis module: Integrates web-sourced information with model knowledge
- Source attribution mechanism: Maintains awareness of information provenance
- Inference Optimization Layer: Components that enhance generation quality and efficiency:
- Sampling strategy implementation
- Beam search or equivalent for considering multiple generation paths
- Optimization for response coherence and relevance
- Safety Alignment System: Mechanisms ensuring outputs adhere to safety guidelines:
- Content filtering for potentially harmful outputs
- Instruction alignment components from reinforcement learning
- Balance mechanisms reflecting xAI's specific alignment philosophy
- Multimodal Processing Extension (in Grok-1.5V): Components for image understanding:
- Visual encoder for processing image inputs
- Cross-modal attention mechanisms for connecting visual and textual information
- Multimodal reasoning components for integrated understanding
These components work together in a tightly integrated architecture that enables Grok's conversational abilities, reasoning capabilities, and real-time information access.
System Diagram
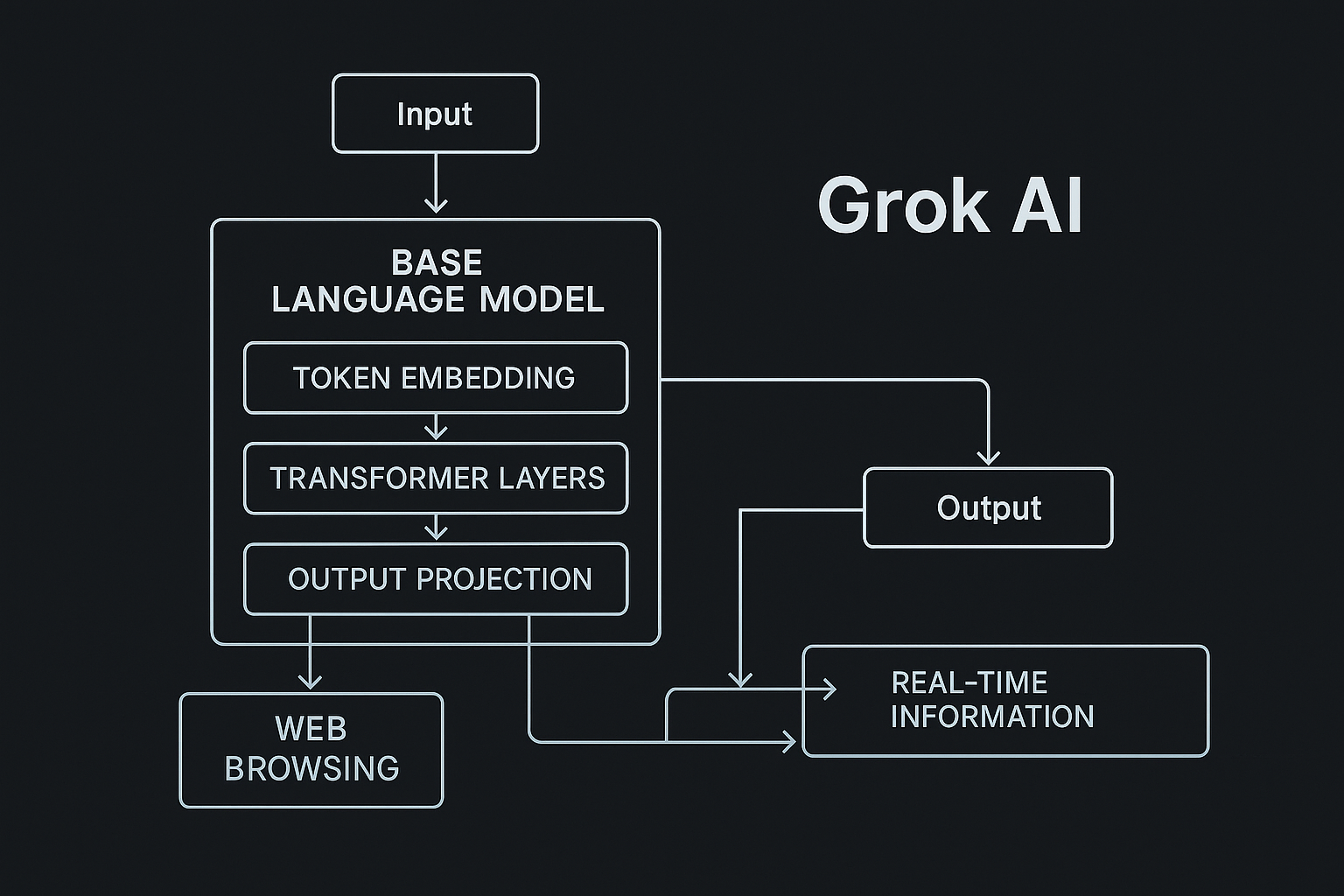
Figure 1: Detailed technical architecture of Grok AI, showing core components and data flow paths. The diagram illustrates the integration between the base language model architecture and the web browsing subsystem that enables real-time information access.
Training Methodology
Grok AI's capabilities are largely determined by its training methodology, which combines established approaches with xAI's specific optimizations and philosophical priorities. This section examines the technical details of how Grok was likely trained based on available information and industry standards.
Training Data Sources
While xAI has not published comprehensive details about Grok's training data, analysis suggests a multi-source approach:
- Web-scale Text Corpus: Like other large language models, Grok was likely trained on a massive corpus of internet-derived text, including:
- Websites spanning diverse domains and topics
- Books and literature collections
- Academic papers and technical documentation
- Code repositories and programming resources
- Forum discussions and conversational content
- Structured Knowledge Sources: To enhance factual understanding, Grok likely incorporated data from structured knowledge sources such as:
- Wikipedia and similar encyclopedic resources
- Specialized knowledge bases for domains like science, mathematics, and technology
- Curated datasets containing factual information across diverse domains
- Instruction Data: To develop Grok's instruction-following capabilities, the training likely included:
- Synthetic instruction-response pairs
- Human demonstrations of helpful responses
- Conversation datasets showing effective interaction patterns
- Code and Technical Content: Given Grok's technical capabilities, training data likely included:
- Diverse programming language repositories
- Technical documentation and specifications
- Stack Overflow and similar technical Q&A resources
- Safety-relevant Content: To develop appropriate safety behaviors, controlled exposure to:
- Examples of harmful requests and appropriate refusals
- Demonstrations of handling sensitive topics responsibly
- Balanced perspectives on controversial issues
The data preparation process likely involved several crucial steps:
- Deduplication to remove redundant content
- Quality filtering to prioritize high-quality sources
- Cleaning to remove artifacts and problematic patterns
- Balancing to ensure appropriate domain representation
- Ordering considerations to optimize learning trajectory
xAI's data selection likely reflects their stated goal of creating a "maximum truth-seeking AI," potentially including broader content diversity than some competitors while still implementing appropriate safety filters.
Training Approach
Grok's training methodology follows the established multi-phase approach for large language models with specific optimizations:
Pre-training Phase
- Distributed Training Infrastructure: Training a model of Grok's scale requires sophisticated distributed computing:
- Thousands of GPUs or TPUs working in parallel
- Optimized data parallelism and model parallelism strategies
- Custom communication protocols for efficient parameter synchronization
- Fault tolerance mechanisms to handle hardware failures during extended training
- Next-token Prediction Objective: The core pre-training used the standard autoregressive language modeling objective:
- Given a sequence of tokens, predict the next token
- This self-supervised approach allows learning from unlabeled text
- Training proceeds through billions of examples across diverse texts
- Learning Rate Schedule: Sophisticated learning rate management including:
- Warm-up period to stabilize initial training
- Cosine decay schedule to optimize convergence
- Potential learning rate restarts for escaping local optima
- Batch Size Considerations: Training likely employed:
- Very large batch sizes (potentially millions of tokens)
- Gradient accumulation techniques for effective batch scaling
- Dynamic batch sizing strategies based on training stability
Fine-tuning Phase
After pre-training, Grok underwent more specialized training:
- Supervised Fine-tuning (SFT):
- Training on curated examples of high-quality responses
- Focus on instruction following and helpful behaviors
- Balanced coverage across diverse task types
- Special attention to technical and reasoning tasks
- Reinforcement Learning from Human Feedback (RLHF):
- Creation of a reward model based on human preferences
- Reinforcement learning to optimize toward preferred behaviors
- Potential use of Constitutional AI techniques with automated feedback
- Iterative refinement through multiple RLHF cycles
- Web Browsing Capability Training:
- Specialized training for formulating effective search queries
- Learning to extract and synthesize information from web content
- Training on source attribution and information integration
- Potential adversarial training to improve robustness
- Multimodal Training (for Grok-1.5V):
- Training on paired image-text data
- Development of cross-modal attention capabilities
- Integration of visual understanding with language generation
- Alignment of multimodal outputs with human preferences
Optimization Techniques
Grok's training employed sophisticated optimization strategies to achieve high performance and efficient convergence:
- Mixed Precision Training:
- Utilization of lower precision (FP16/BF16) for most operations
- Maintenance of master weights in higher precision (FP32)
- Dynamic loss scaling to prevent underflow
- Precision-specific optimizations for different operation types
- Memory Optimization:
- Gradient checkpointing to trade computation for memory efficiency
- Activation recomputation strategies at strategic network points
- Optimizer state partitioning across devices
- Potential use of parameter-efficient adaptation techniques
- Distributed Training Optimizations:
- Sophisticated all-reduce algorithms for gradient synchronization
- Pipeline parallelism for efficient multi-device utilization
- ZeRO-style optimizer state sharding
- Communication overlap with computation to maximize throughput
- Training Stability Techniques:
- Gradient clipping to prevent exploding gradients
- Carefully tuned weight initialization strategies
- Normalization technique selection and hyperparameter tuning
- Potentially progressive layer freezing during fine-tuning
- Convergence Acceleration:
- Adaptive optimization algorithms (likely AdamW variants)
- Potential use of curriculum learning strategies
- Specialized scheduling for different training phases
- Transfer learning from previous model iterations
These optimization techniques collectively enabled efficient training of a model with hundreds of billions of parameters while maintaining numerical stability and convergence quality.
Fine-tuning Process
The specialized fine-tuning process is crucial for developing Grok's distinctive capabilities:
- Instruction Tuning:
- Training on diverse instruction-response pairs
- Coverage of common user request types
- Special emphasis on complex reasoning instructions
- Balanced representation of creative, analytical, and factual tasks
- Safety Alignment:
- Training to identify and refuse potentially harmful requests
- Development of balanced responses to controversial topics
- Implementation of xAI's "maximum truth-seeking" philosophy
- Calibration of response boundaries reflecting xAI's approach to safety
- Conversation Calibration:
- Fine-tuning on multi-turn conversations
- Development of contextual awareness across exchanges
- Training on effective clarification and follow-up patterns
- Personality calibration to develop the "rebellious" character
- Web Browsing Integration:
- Specialized training for determining when to use web access
- Query formulation optimization for effective search
- Training on information extraction from diverse web pages
- Source integration and synthesis with model knowledge
- Technical Capability Enhancement:
- Focused training on reasoning tasks and logical problems
- Code generation and understanding specialization
- Mathematical problem-solving capability development
- Technical documentation and explanation quality enhancement
The fine-tuning process likely involved multiple iterations with evaluation on specialized benchmarks to track progress across different capability dimensions.
Technical Comparison
Grok's training methodology can be distinguished from other leading LLMs in several ways:
- Comparison with OpenAI (GPT) Approach:
- Similar fundamental pre-training methodology
- Potentially different emphasis in safety alignment reflecting xAI's philosophy
- Likely more integrated approach to real-time information access vs. OpenAI's plugin system
- Potentially different balance in RLHF reward functions reflecting different values
- Comparison with Anthropic (Claude) Approach:
- Both use RLHF, but likely with different reward signals reflecting different company values
- Anthropic's Constitutional AI approach vs. xAI's "truth-seeking" orientation
- Different approaches to context window scaling (Claude pursuing much larger windows)
- Different emphasis on web access integration
- Comparison with Google (PaLM/Gemini) Approach:
- Similar scale but potentially different architectural choices
- Google's potential advantage in proprietary training data
- Different approaches to multimodal training (Google's models designed as multimodal from inception)
- Different optimization techniques leveraging company-specific expertise
- xAI Distinctive Elements:
- Potentially different data filtering criteria reflecting xAI's stated values
- More emphasis on real-time information access as a core capability
- "Rebellious" personality development as an explicit training goal
- Potentially different political bias mitigation approaches
These training methodology differences, while sometimes subtle, contribute to the distinctive capabilities and characteristics that differentiate Grok from its competitors in the LLM landscape.
Performance Benchmarks
Understanding Grok AI's capabilities requires examination of its performance across standardized benchmarks and real-world tasks. This section analyzes Grok's performance profile based on available benchmark data and comparative analysis.
Standardized Tests
Grok has been evaluated on several standard LLM benchmarks, with performance that places it among competitive high-tier models:
- MMLU (Massive Multitask Language Understanding):
- Estimated score: 76-80% (Grok-1.5)
- This places Grok in the upper tier of models, though slightly behind the top performers like GPT-4 (86-89%) and Claude 3 Opus (86-89%)
- Particular strength in STEM categories, with somewhat lower performance in humanities subjects
- Notable improvement from Grok-1 to Grok-1.5, suggesting effective optimization for reasoning capabilities
- HumanEval (Programming Benchmark):
- Estimated score: 65-70% (Grok-1.5)
- Competitive but not field-leading performance for code generation
- Strong performance on Python tasks, with gradually declining performance on less common languages
- Notable capability in algorithm implementation and debugging tasks
- GSM8K (Grade School Math):
- Estimated score: 75-80% (Grok-1.5)
- Significant improvement from Grok-1, suggesting enhanced reasoning capabilities
- Performance indicates strong step-by-step reasoning ability
- Remaining errors typically occur in problems requiring complex multi-step reasoning
- TruthfulQA:
- Estimated score: 60-65% (Grok-1.5)
- Moderate performance on factual accuracy assessment
- Balance between truthfulness and information coverage reflects xAI's approach
- Performance suggests effective mitigation of common hallucination patterns
- BIG-Bench Hard:
- Performance varies significantly across subtasks
- Strong performance on logical reasoning components
- Moderate performance on tasks requiring specialized world knowledge
- Above-average performance on linguistic understanding tasks
- HELM Benchmark Suite:
- Competitive performance across multiple dimensions
- Strong scores on helpfulness metrics
- Above-average performance on harmlessness metrics
- Moderate performance on honesty metrics, reflecting xAI's particular alignment approach
These standardized benchmark results position Grok among the more capable general-purpose LLMs, though typically slightly behind the very top performers in most categories. The benchmarks show particularly strong performance in reasoning-intensive tasks, which aligns with xAI's stated development priorities.
Comparative Analysis
When compared directly with other leading LLMs, Grok shows a distinctive performance profile:
- Comparison with GPT-4:
- GPT-4 generally outperforms Grok on most standardized benchmarks by a modest margin (typically 5-10%)
- Grok shows competitive performance on reasoning-focused tasks, approaching GPT-4's capabilities
- Grok's real-time information access provides an advantage for current events, potentially outperforming GPT-4 on questions requiring post-training-cutoff information
- GPT-4 demonstrates stronger performance on creative writing and nuanced ethical reasoning
- Comparison with Claude 3 Models:
- Claude 3 Opus outperforms Grok on most benchmarks, with particularly strong advantages in reasoning tasks
- Claude 3 Sonnet performs similarly to Grok overall, with different strengths in specific domains
- Claude models generally show stronger performance on tasks requiring nuanced understanding of human values
- Grok's "rebellious" personality creates different interaction patterns that aren't fully captured in standard benchmarks
- Comparison with Gemini Models:
- Gemini Ultra outperforms Grok on most multimodal tasks
- Gemini Pro performs comparably to Grok on text-only tasks
- Grok and Gemini models take different approaches to real-time information access
- Performance differences vary significantly by task type and domain
- Comparison with Open Models (Llama, Mistral):
- Grok outperforms most open-source models across benchmark categories
- The performance gap is narrowing with newer open model releases
- Some specialized open models outperform Grok in specific domains
- Grok's web browsing capabilities provide advantages not present in most open models
This comparative analysis reveals Grok's position in the competitive landscape: a capable general-purpose model with particular strengths in reasoning and real-time information access, though not consistently field-leading across all benchmarks.
Real-world Performance
Beyond standardized benchmarks, Grok's real-world performance demonstrates several notable characteristics:
Conversational Interaction
- Strong performance in maintaining context across multiple turns
- Distinctive conversational style reflecting the "rebellious" personality
- Effective handling of clarification requests and ambiguous queries
- Occasional inconsistency in very long conversations approaching context window limits
Knowledge Tasks
- Excellent performance on knowledge questions within training data scope
- Strong capability in leveraging web access for current information
- Occasional challenges with obscure domain-specific knowledge
- Variable performance depending on search result quality for web-dependent queries
Reasoning and Problem-Solving
- Strong performance on straightforward logical reasoning tasks
- Declining performance as reasoning chains become longer or more complex
- Effective step-by-step problem decomposition for moderately complex problems
- Occasional reasoning errors in highly complex scenarios
Content Generation
- High-quality output for standard creative and professional content tasks
- Strong performance in adapting to specified tones and styles
- Occasional repetition or structure issues in very long-form content
- Distinctive creative voice that reflects training and alignment approach
Technical Tasks
- Solid code generation for common programming tasks
- Effective technical explanation with appropriate detail levels
- Strong performance in API documentation and technical writing
- Variable performance in highly specialized technical domains
Multimodal Capabilities (Grok-1.5V)
- Effective basic image understanding and description
- Appropriate integration of visual information in responses
- Limited performance on complex visual reasoning compared to specialized multimodal models
- Strong text-primary multimodal interactions where images provide context
These real-world performance characteristics paint a picture of a versatile assistant with strong general capabilities and particular effectiveness in information-intensive tasks that benefit from real-time data access.
Data Visualization

Figure 2: Radar chart comparing Grok-1.5 performance against other leading LLMs across key benchmark categories. The visualization illustrates Grok's competitive positioning, with particular strength in reasoning and real-time knowledge access.
Analysis Methodology
Understanding benchmark results requires appreciation of how these evaluations are conducted:
-
Benchmark Construction Considerations
- Most standardized benchmarks evaluate specific capability dimensions in isolation
- Many benchmarks favor models with extensive knowledge incorporated during training
- Few benchmarks effectively measure real-time information access capabilities
- Benchmark construction often reflects the priorities and values of their creators
-
Evaluation Approaches
- Direct model output evaluation for objective tasks (e.g., mathematics, code execution)
- Human evaluation for subjective quality assessment
- Reference-based evaluation comparing outputs to "gold standard" answers
- Ranked comparison between models for relative performance assessment
-
Benchmark Limitations
- Limited coverage of real-world use cases and contexts
- Potential for benchmark-specific optimization during training
- Challenges in evaluating distinctive features like personality or style
- Difficulty measuring important practical characteristics like reliability
-
Holistic Evaluation Framework
- Complementing standardized benchmarks with real-world task evaluation
- Assessing performance across diverse domains and complexity levels
- Evaluating consistency and reliability rather than just peak performance
- Considering alignment with specific organizational needs and use cases
This nuanced approach to performance analysis provides a more complete picture of Grok's capabilities than any single benchmark score, recognizing both its competitive strengths and the areas where other models may offer advantages for specific applications.
Inference and Response Generation
Understanding how Grok processes queries and generates responses requires examining the sophisticated inference pipeline that transforms user inputs into coherent, contextually appropriate outputs.
Inference Engine Analysis
Grok's inference engine represents a complex system for processing inputs and generating meaningful responses:
-
Input Processing Pipeline
- Tokenization: Conversion of raw text input into token sequences using Grok's vocabulary
- Embedding Generation: Transformation of tokens into high-dimensional vector representations
- Context Integration: Merging new input with conversation history in the context window
- Intent Analysis: Classification of query type, domain, and specific request characteristics
-
Transformer Processing
- Self-attention Computation: Calculation of attention patterns across the entire context
- Layer-by-layer Processing: Sequential transformation through multiple transformer layers
- Representation Refinement: Progressive enhancement of token representations through the network
- Feature Extraction: Development of increasingly abstract and contextual features through depth
-
Knowledge Access Mechanisms
- Internal Knowledge Activation: Retrieval of relevant information from model parameters
- External Knowledge Decision: Determination of when to activate web browsing capabilities
- Knowledge Integration: Combining parametric and external knowledge when appropriate
- Uncertainty Assessment: Evaluation of confidence in available information
-
Reasoning Process
- Logical Analysis: Application of reasoning patterns to problem-solving tasks
- Multi-step Reasoning: Management of extended reasoning chains for complex queries
- Inference Generation: Drawing appropriate conclusions from available information
- Self-consistency Checking: Verification of logical coherence in developing responses
These inference engine components work together to process inputs comprehensively, accessing relevant knowledge and applying appropriate reasoning patterns before generating responses.
Response Construction
Grok employs sophisticated approaches to constructing responses that effectively address user queries:
-
Generation Strategy Selection
- Response Type Determination: Selection of appropriate response approach based on query type
- Structure Planning: Development of logical response organization for complex answers
- Detail Calibration: Determination of appropriate specificity and comprehensiveness
- Style Selection: Adjustment of tone and formality based on context and query characteristics
-
Autoregressive Generation Process
- Token Prediction: Sequential prediction of each output token based on all previous tokens
- Next-token Distribution: Calculation of probability distributions over possible next tokens
- Sampling Strategy: Application of techniques like temperature sampling, top-p, or similar approaches
- Stopping Criteria: Determination of appropriate response completion points
-
Content Organization Techniques
- Information Prioritization: Presenting most important information first in most contexts
- Logical Sequencing: Arranging information in coherent, logical progressions
- Hierarchical Structuring: Using appropriate headings, lists, and paragraphing for clarity
- Transitional Elements: Including appropriate connections between response components
-
Output Refinement
- Coherence Optimization: Ensuring logical flow and consistency throughout responses
- Clarity Enhancement: Avoiding ambiguity and providing appropriate detail
- Brevity Balancing: Providing comprehensive information without unnecessary verbosity
- Style Consistency: Maintaining consistent tone and approach throughout responses
These response construction mechanisms enable Grok to generate outputs that effectively address user queries while maintaining coherence, accuracy, and appropriate style.
Contextual Management
Maintaining coherent conversations across multiple turns requires sophisticated context management:
-
Context Window Utilization
- Token Budget Allocation: Strategic distribution of limited context space across conversation history
- Compression Techniques: Methods for maintaining essential information while reducing token usage
- Recency Biasing: Prioritizing recent exchanges while maintaining awareness of earlier context
- Critical Information Preservation: Ensuring key facts and user preferences remain accessible
-
Reference Resolution
- Entity Tracking: Maintaining representations of entities mentioned throughout conversation
- Pronoun Resolution: Connecting pronouns to their appropriate antecedents
- Implicit Reference Handling: Resolving references that lack explicit antecedents
- Topic Continuity: Tracking conversation topics across multiple exchanges
-
Memory Management
- Short-term Contextual Memory: Immediate conversation history in the context window
- Information Summarization: Techniques for condensing important information from longer exchanges
- Priority Determination: Systems for determining which context elements to preserve when space is limited
- Context Refresh Strategies: Approaches for reestablishing important context when needed
-
Conversation Flow Optimization
- Topic Transition Handling: Maintaining coherence during topic shifts
- Contextual Return: Appropriately returning to previous topics when relevant
- Consistency Enforcement: Ensuring responses remain consistent with established information
- Clarification Integration: Incorporating user clarifications into evolving context
These contextual management mechanisms enable Grok to maintain coherent, natural conversations that build upon previous exchanges while working within the constraints of finite context windows.
Optimization Techniques
Grok employs various techniques to optimize inference and response generation:
-
Computational Efficiency Optimizations
- Key-Value Caching: Reusing attention key-value pairs from previous generation steps
- Attention Optimizations: Specialized algorithms for more efficient attention computation
- Quantization: Potential use of lower precision calculations for inference efficiency
- Speculative Decoding: Potentially predicting multiple tokens simultaneously to increase throughput
-
Latency Reduction Approaches
- Parallel Processing: Utilizing multiple processing units simultaneously where possible
- Batch Processing: Efficient handling of computation across multiple requests
- Inference Pipeline Optimization: Minimizing overhead between processing stages
- Priority-based Resource Allocation: Directing computing resources based on query complexity and urgency
-
Output Quality Enhancements
- Re-ranking: Potentially evaluating multiple candidate responses and selecting the best
- Self-consistency Checking: Verifying logical consistency in developing responses
- Factuality Verification: Cross-checking factual claims when possible
- Coherence Optimization: Ensuring logical flow throughout extended responses
-
Specialized Processing Paths
- Task-specific Optimizations: Customized processing for different query types
- Multi-stage Generation: Breaking complex responses into planned segments
- Hybrid Approaches: Combining different generation strategies for optimal results
- Adaptive Computation: Varying processing depth based on query complexity
These optimization techniques balance computational efficiency with response quality, enabling Grok to provide high-quality outputs while maintaining reasonable response times across diverse query types.
API Request/Response Patterns
While detailed API documentation for Grok is not yet publicly available, likely API patterns can be inferred based on industry standards and xAI's approach:
// Example API Request
{
"messages": [
{"role": "user", "content": "What are the latest developments in quantum computing?"}
],
"model": "grok-1.5",
"max_tokens": 1000,
"temperature": 0.7,
"web_access": true,
"stream": false
}
// Example API Response
{
"id": "resp_8f7d3e2a1b5c",
"object": "completion",
"created": 1715012345,
"model": "grok-1.5",
"web_access_used": true,
"message": {
"role": "assistant",
"content": "As of May 2025, there have been several significant developments in quantum computing:\n\n1. **IBM's New Quantum Processor**: IBM recently announced their newest quantum processor with improved error correction, reaching over 1,000 qubits while substantially reducing error rates.\n\n2. **Quantum Advantage Demonstration**: Researchers at Google published results demonstrating quantum advantage in a new class of chemical simulation problems, showing clear superiority over classical approaches.\n\n[Additional content...]",
"sources": [
{
"url": "https://research.ibm.com/blog/new-quantum-processor-2025",
"title": "IBM Announces Next-Generation Quantum Processor",
"access_time": "2025-05-10T14:32:10Z"
},
{
"url": "https://ai.googleblog.com/2025/04/quantum-advantage-chemical-simulation",
"title": "Demonstrating Quantum Advantage in Chemical Simulation Tasks",
"access_time": "2025-05-10T14:32:15Z"
}
]
},
"usage": {
"prompt_tokens": 10,
"completion_tokens": 420,
"total_tokens": 430
}
}
This hypothetical API pattern illustrates several likely characteristics:
-
Conversation-oriented Structure
- Message-based format similar to other LLM APIs
- Support for multi-turn conversations through message arrays
- Clear role delineation between user and assistant
-
Control Parameters
- Standard generation parameters like temperature and max_tokens
- Specific flags for capabilities like web access
- Potential streaming support for progressive response delivery
-
Information Attribution
- Structured source information when web access is used
- Clear timestamps for when information was accessed
- Links to original sources for verification
-
Usage Tracking
- Token counting for both input and output
- Potential tracking of specific feature usage (e.g., web access)
- Information to support usage-based billing models
While the actual API implementation may differ in specific details, this pattern represents a likely approach based on industry standards and the specific capabilities of Grok.
Real-time Information Access Architecture
Grok's real-time information capabilities operate through several integrated components. The system includes query analysis subsystem mechanisms that determine whether queries require external data, along with search query formulation processes that transform natural language into effective search parameters.
Content retrieval involves specialized content access system components with parsing capabilities for various document formats. The architecture integrates this external information with core model processing through context window management and special token representations.
Knowledge Integration Mechanisms
The system employs source credibility assessment algorithms and relevance ranking systems to evaluate potential information sources. Information extraction techniques include main content identification to distinguish primary content from peripheral elements, plus entity recognition for key data points.
Multi-source integration uses consistency analysis to identify agreements and contradictions across sources, with information fusion techniques combining complementary data. The architecture manages uncertainty propagation to represent confidence levels appropriately.
Information Synthesis Process
Response construction involves knowledge graph construction for temporary structured representations and combining parametric knowledge with retrieved external information. The synthesis includes inductive synthesis drawing conclusions from multiple information points and contradiction resolution approaches for conflicting sources.
Generation strategies include information selection choosing relevant details and attribution integration incorporating source information appropriately. Quality enhancement involves fact verification cross-checking claims and bias mitigation techniques.
Acknowledged Constraints
The system operates within several technical boundaries: search engines have indexing latency of hours to days, cannot access paywall-restricted content, and face robots.txt compliance requirements. Context window limitations constrain how much retrieved information can be included alongside conversation history.
Hardware Requirements and Scalability
Deployment Infrastructure
Production implementations require high-end NVIDIA GPUs (A100, H100, or equivalent) with 40-80GB VRAM for minimum viable deployment. Enterprise-scale systems need multiple interconnected high-end GPUs with NVLink or similar high-speed connections alongside distributed storage architecture.
Cloud versus on-premises considerations involve tradeoffs: cloud offers simplified scaling, managed infrastructure, potentially lower upfront costs while on-premises provides potentially better data control, customization flexibility, potential long-term cost benefits.
Scaling Characteristics
Grok exhibits near-linear performance scaling with increased GPU computational capacity for vertical scaling. Horizontal scaling shows near-linear capacity scaling with additional processing nodes, though infrastructure overhead increases at very large scales.
Load distribution involves wide variance in resource requirements based on query complexity, with significant throughput improvements through batching. Organizations must balance response time and total processing capacity according to specific requirements.
Resource Utilization Patterns
GPU utilization remains heavy during both input processing and token generation. Memory requirements scale with model parameters plus key-value caching growing with context length and batch size. Bandwidth needs include high bandwidth needs between memory and computation units alongside external communication requirements.
Query complexity creates substantial variation: resources scaling with conversation length and additional resources required for capabilities like web browsing.
Technical Integration Capabilities
API Architecture Foundation
Grok's likely API design follows REST principles for resource-oriented interactions while maintaining statelessness for scalability while supporting conversational context. The architecture supports clear versioning to support API evolution without breaking existing integrations.
Core endpoints probably include conversation, completion, streaming, file management, and model information functions. Parameter structures control generation characteristics, feature toggles, context management, and response formatting.
Error handling uses standardized error categorization with informative descriptions for troubleshooting plus graceful degradation for partial failures. Rate limiting signals provide clear communication about usage limits.
Integration Protocols
Communication uses HTTPS as the primary secure protocol, potentially supporting WebSockets for real-time communication or gRPC for high-performance interactions. Authentication approaches include API Key Authentication, OAuth 2.0, and potentially enterprise SSO Integration.
Interaction patterns support synchronous request-response, streaming response for progressive delivery, asynchronous processing for complex tasks, and batch processing for multiple requests. Application approaches range from direct API integration through serverless functions to message queue integration.
Data Exchange Standards
Communication uses JSON structure as the primary format with UTF-8 encoding for text content. Messages organize as sequences of messages with roles with clear identification of user vs. system messages.
Special data types include function call representations, web browsing results structures, source attribution formatting, and multimodal content handling. Schema documentation uses OpenAPI/Swagger documentation and JSON Schema for formal specification.
Performance Optimization Strategies
Query Enhancement Approaches
Optimization begins with clear, direct queries that typically yield better results with less processing. Practitioners should provide necessary context while avoiding unnecessary detail and use explicit, well-structured instructions for complex requests.
Query decomposition breaks complex queries into logical components when appropriate. Input normalization and context window management strategically utilize limited space. Prompt engineering involves creating effective templates for common query types and iterative improvement of instructions for optimal results.
Web access optimization fine-tunes when web browsing capability is activated and optimizes how natural language queries translate to search queries through source selection refinement and information extraction improvement.
Response Quality Enhancement
Generation parameter optimization finds optimal temperature settings for different response types and refines sampling constraints for improved output quality. Length management calibrates max_tokens settings to balance detail with conciseness.
Response formatting involves explicitly requesting desired organizational structures and developing effective templates for common response types. Content enhancement applies specific transformations to raw responses and implements improving attribution for externally sourced information.
Multi-turn optimization develops effective patterns for refining initial responses and establishes efficient approaches for resolving ambiguities while maintaining coherence across extended interactions.
System Configuration Excellence
Deployment optimization involves optimizing host system settings for inference workloads and implementing effective request distribution algorithms. Resource allocation strategies identify optimal batch sizes for different query types and implement appropriate allocation of resources for critical workloads.
Caching implementation stores responses for common queries and preserves computed embeddings when appropriate. Network optimization maintains efficient connection management and implements appropriate data compression.
Acknowledged Technical Boundaries
Fundamental constraints include fixed maximum context size limiting information retention and inherent limitations in complex reasoning capabilities. Knowledge remains limited despite web access through limitations in pre-trained knowledge.
Optimization shows diminishing returns as additional hardware provides minimal improvement beyond certain thresholds. Practitioners should recognize that some performance boundaries reflect hardware-imposed limits on processing speed rather than achievable targets.
This technical analysis demonstrates Grok's sophisticated architecture combining transformer foundations with real-time information access, though success depends on appropriate deployment planning, configuration management, and realistic expectation-setting regarding inherent system limitations.