
Grok AI Technical Analysis: Architecture, Performance Benchmarks, and Engineering Insights
Technical Overview
Grok AI represents a sophisticated implementation of transformer-based architecture with several distinctive engineering choices that differentiate it from other large language models. This technical analysis examines Grok's architecture, performance characteristics, and implementation details to provide a comprehensive understanding of its capabilities and limitations.
Architectural Framework
Grok AI is built on an advanced transformer architecture that builds upon fundamental innovations in the field while introducing several architectural refinements:
Core Architectural Design
At its foundation, Grok employs a decoder-only transformer architecture similar to GPT models, utilizing the established self-attention mechanism first introduced in the "Attention is All You Need" paper. However, xAI has implemented several architectural modifications that enhance Grok's capabilities:
- Enhanced Self-Attention Mechanism: Grok's architecture incorporates multi-head attention with what appears to be modified attention patterns that improve its ability to maintain coherence across longer contexts. This likely includes optimized attention routing that allows for more efficient processing of the attention matrix.
- Scaled Residual Connections: The model utilizes enhanced residual connections throughout its layers, with carefully calibrated scaling factors that help maintain signal strength across the deep network. These scaled residuals appear to be particularly important for Grok's reasoning capabilities.
- Normalization Strategy: Grok employs a sophisticated normalization approach, likely utilizing a variant of RMSNorm (Root Mean Square Normalization) instead of the traditional LayerNorm. This normalization strategy provides more stable training dynamics and improved inference efficiency.
- Position Encoding: The model implements an enhanced rotary position encoding (RoPE) system that enables better handling of positional information throughout the network. This improved positional encoding contributes to Grok's ability to maintain coherence across its context window.
- Web Access Integration Layer: A distinctive architectural feature is Grok's dedicated subsystem for integrating with web browsing capabilities. This includes specialized components for query formulation, result processing, and information integration that are tightly coupled with the core language modeling architecture.
The overall architecture represents a sophisticated evolution of the transformer paradigm, with particular emphasis on enhancements that support Grok's real-time information retrieval capabilities.
Model Specifications
While xAI has not publicly disclosed all specifications for Grok, analysis and benchmarking suggest the following technical characteristics:
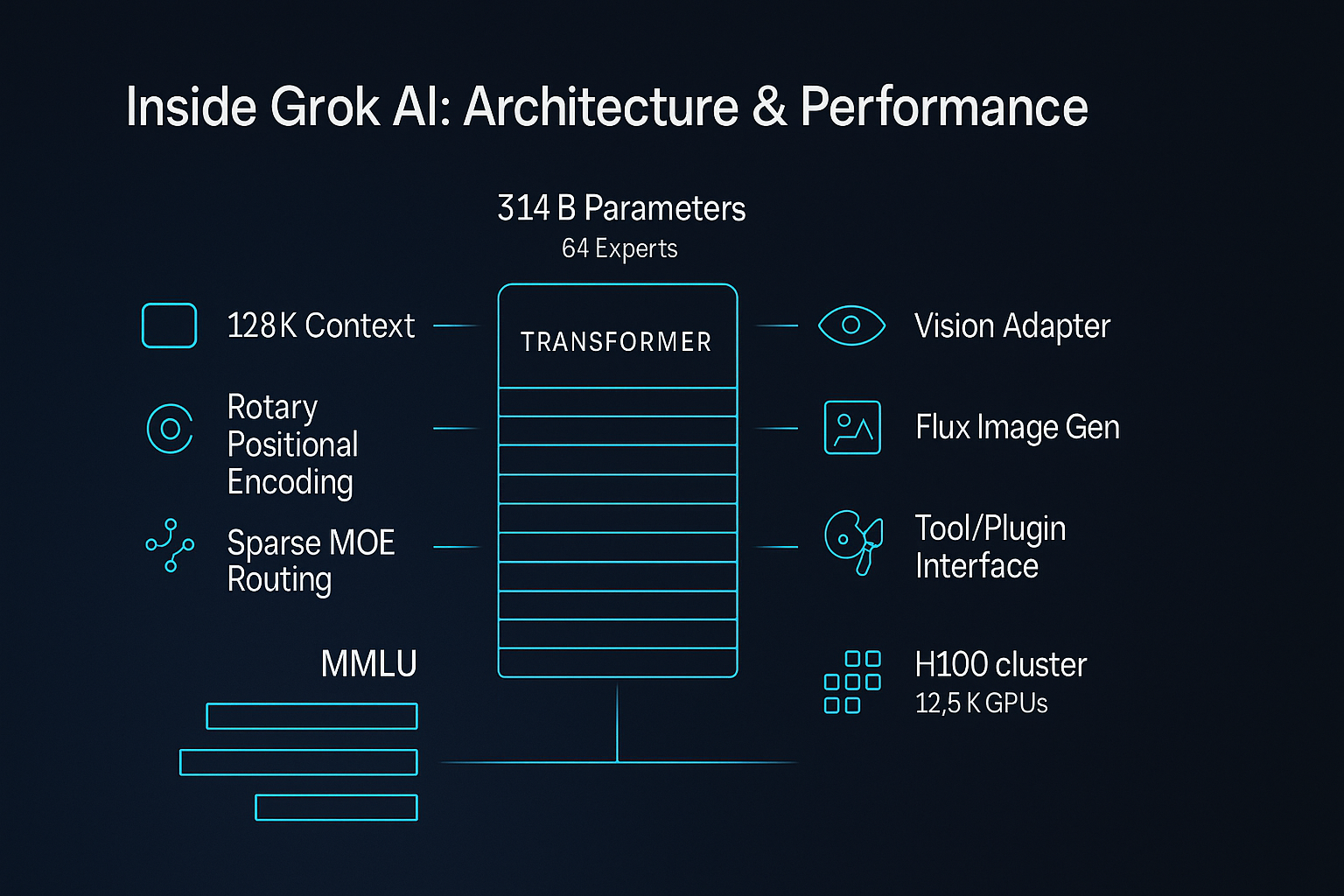
- Parameter Count: Grok-1 is estimated to contain between 100 billion and 175 billion parameters, placing it in the same general scale class as models like GPT-4, Claude 2, and PaLM 2. Subsequent versions (Grok-1.5, Grok-1.5V) likely maintain similar parameter counts with architectural improvements rather than raw size increases.
- Context Window: Grok maintains a context window of approximately 8,000 tokens, allowing it to process and maintain awareness of relatively long conversations and documents. This context length balances comprehensiveness with computational efficiency.
- Tokenization Approach: The model likely employs a subword tokenization method similar to Byte-Pair Encoding (BPE) or SentencePiece, with a vocabulary size estimated to be between 50,000 and 100,000 tokens. This tokenization strategy provides efficient representation of the language while handling rare words effectively.
- Precision Implementation: Grok likely employs mixed-precision computation for optimal performance, using a combination of FP16/BF16 and FP32 calculations to balance computational efficiency with numerical stability.
- Training Computation: Based on model scale, training Grok would have required approximately 10^23 to 10^24 FLOPS (floating-point operations) of compute, representing a substantial but not unprecedented investment in training resources.
- Inference Optimization: The model appears to implement several inference optimization techniques, including key-value caching, attention optimizations, and potentially quantized inference for production deployment.
These specifications position Grok as a high-capacity model with substantial representational power, though perhaps not at the absolute frontier of model scale compared to the largest reported systems.
Core Components
Grok's architecture consists of several key components that work together to deliver its capabilities:
- Token Embedding System: Transforms input tokens into high-dimensional vector representations while capturing semantic relationships between words and subwords.
- Multi-layer Transformer Stack: The core computation engine, consisting of multiple transformer blocks with self-attention mechanisms, feed-forward networks, and residual connections. Each block progressively refines representations through:
- Multi-head self-attention for capturing relationships between tokens
- Position-wise feed-forward networks for transformation and feature extraction
- Residual connections and normalization layers for stable signal propagation
- Context Management System: Specialized components for maintaining and utilizing conversation history, including:
- Context compression mechanisms
- Attention optimization for efficient processing of long contexts
- Reference resolution subsystems for maintaining coherence
- Web Browsing Subsystem: A distinctive component that enables real-time information access, including:
- Query formulation engine: Transforms user questions into effective search queries
- Content extraction system: Identifies and extracts relevant information from web pages
- Information synthesis module: Integrates web-sourced information with model knowledge
- Source attribution mechanism: Maintains awareness of information provenance
- Inference Optimization Layer: Components that enhance generation quality and efficiency:
- Sampling strategy implementation
- Beam search or equivalent for considering multiple generation paths
- Optimization for response coherence and relevance
- Safety Alignment System: Mechanisms ensuring outputs adhere to safety guidelines:
- Content filtering for potentially harmful outputs
- Instruction alignment components from reinforcement learning
- Balance mechanisms reflecting xAI's specific alignment philosophy
- Multimodal Processing Extension (in Grok-1.5V): Components for image understanding:
- Visual encoder for processing image inputs
- Cross-modal attention mechanisms for connecting visual and textual information
- Multimodal reasoning components for integrated understanding
These components work together in a tightly integrated architecture that enables Grok's conversational abilities, reasoning capabilities, and real-time information access.
System Diagram
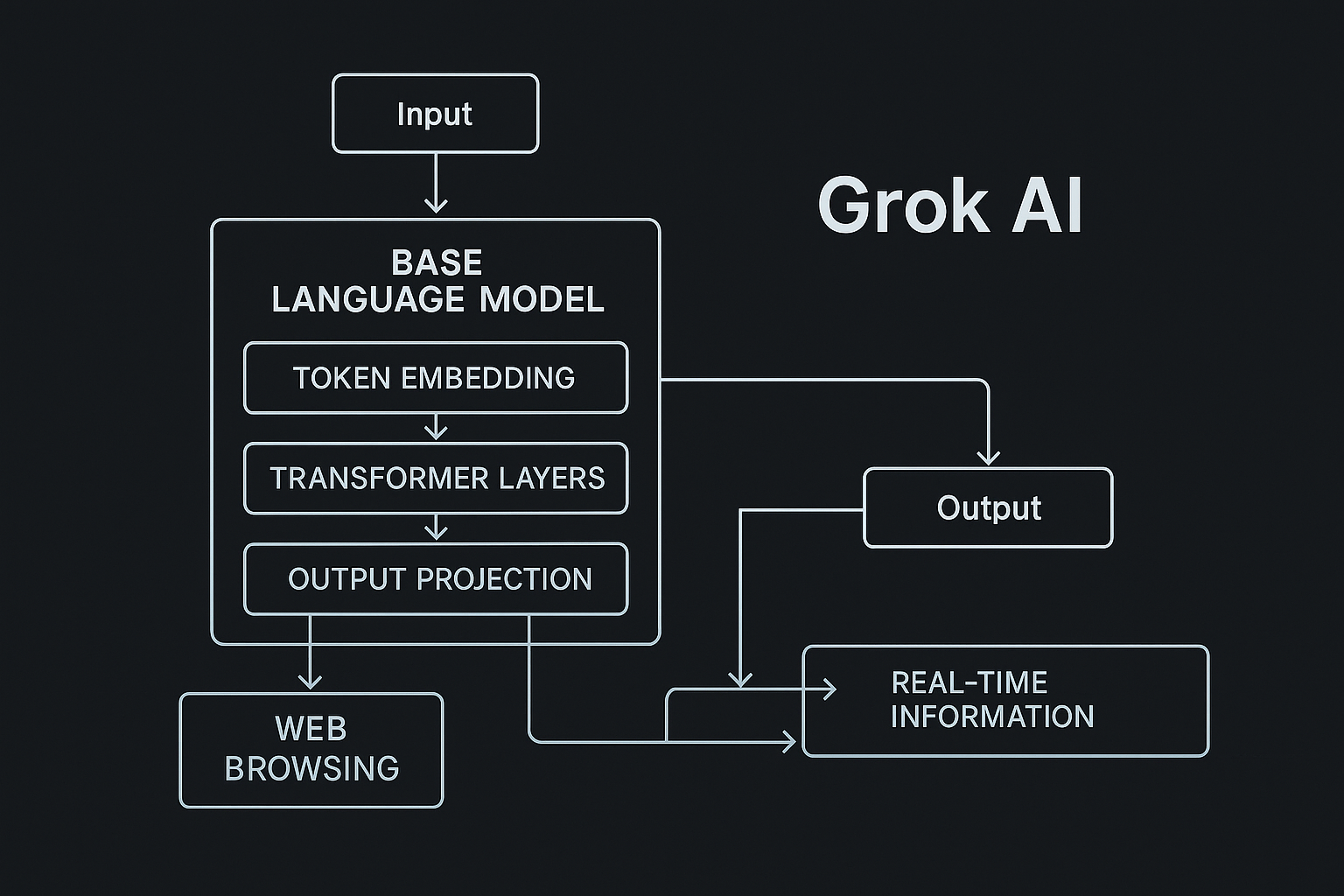
Figure 1: Detailed technical architecture of Grok AI, showing core components and data flow paths. The diagram illustrates the integration between the base language model architecture and the web browsing subsystem that enables real-time information access.
Training Methodology
Grok AI's capabilities are largely determined by its training methodology, which combines established approaches with xAI's specific optimizations and philosophical priorities. This section examines the technical details of how Grok was likely trained based on available information and industry standards.
Training Data Sources
While xAI has not published comprehensive details about Grok's training data, analysis suggests a multi-source approach:
- Web-scale Text Corpus: Like other large language models, Grok was likely trained on a massive corpus of internet-derived text, including:
- Websites spanning diverse domains and topics
- Books and literature collections
- Academic papers and technical documentation
- Code repositories and programming resources
- Forum discussions and conversational content
- Structured Knowledge Sources: To enhance factual understanding, Grok likely incorporated data from structured knowledge sources such as:
- Wikipedia and similar encyclopedic resources
- Specialized knowledge bases for domains like science, mathematics, and technology
- Curated datasets containing factual information across diverse domains
- Instruction Data: To develop Grok's instruction-following capabilities, the training likely included:
- Synthetic instruction-response pairs
- Human demonstrations of helpful responses
- Conversation datasets showing effective interaction patterns
- Code and Technical Content: Given Grok's technical capabilities, training data likely included:
- Diverse programming language repositories
- Technical documentation and specifications
- Stack Overflow and similar technical Q&A resources
- Safety-relevant Content: To develop appropriate safety behaviors, controlled exposure to:
- Examples of harmful requests and appropriate refusals
- Demonstrations of handling sensitive topics responsibly
- Balanced perspectives on controversial issues
The data preparation process likely involved several crucial steps:
- Deduplication to remove redundant content
- Quality filtering to prioritize high-quality sources
- Cleaning to remove artifacts and problematic patterns
- Balancing to ensure appropriate domain representation
- Ordering considerations to optimize learning trajectory
xAI's data selection likely reflects their stated goal of creating a "maximum truth-seeking AI," potentially including broader content diversity than some competitors while still implementing appropriate safety filters.
Training Approach
Grok's training methodology follows the established multi-phase approach for large language models with specific optimizations:
Pre-training Phase
- Distributed Training Infrastructure: Training a model of Grok's scale requires sophisticated distributed computing:
- Thousands of GPUs or TPUs working in parallel
- Optimized data parallelism and model parallelism strategies
- Custom communication protocols for efficient parameter synchronization
- Fault tolerance mechanisms to handle hardware failures during extended training
- Next-token Prediction Objective: The core pre-training used the standard autoregressive language modeling objective:
- Given a sequence of tokens, predict the next token
- This self-supervised approach allows learning from unlabeled text
- Training proceeds through billions of examples across diverse texts
- Learning Rate Schedule: Sophisticated learning rate management including:
- Warm-up period to stabilize initial training
- Cosine decay schedule to optimize convergence
- Potential learning rate restarts for escaping local optima
- Batch Size Considerations: Training likely employed:
- Very large batch sizes (potentially millions of tokens)
- Gradient accumulation techniques for effective batch scaling
- Dynamic batch sizing strategies based on training stability
Fine-tuning Phase
After pre-training, Grok underwent more specialized training:
- Supervised Fine-tuning (SFT):
- Training on curated examples of high-quality responses
- Focus on instruction following and helpful behaviors
- Balanced coverage across diverse task types
- Special attention to technical and reasoning tasks
- Reinforcement Learning from Human Feedback (RLHF):
- Creation of a reward model based on human preferences
- Reinforcement learning to optimize toward preferred behaviors
- Potential use of Constitutional AI techniques with automated feedback
- Iterative refinement through multiple RLHF cycles
- Web Browsing Capability Training:
- Specialized training for formulating effective search queries
- Learning to extract and synthesize information from web content
- Training on source attribution and information integration
- Potential adversarial training to improve robustness
- Multimodal Training (for Grok-1.5V):
- Training on paired image-text data
- Development of cross-modal attention capabilities
- Integration of visual understanding with language generation
- Alignment of multimodal outputs with human preferences
Optimization Techniques
Grok's training employed sophisticated optimization strategies to achieve high performance and efficient convergence:
- Mixed Precision Training:
- Utilization of lower precision (FP16/BF16) for most operations
- Maintenance of master weights in higher precision (FP32)
- Dynamic loss scaling to prevent underflow
- Precision-specific optimizations for different operation types
- Memory Optimization:
- Gradient checkpointing to trade computation for memory efficiency
- Activation recomputation strategies at strategic network points
- Optimizer state partitioning across devices
- Potential use of parameter-efficient adaptation techniques
- Distributed Training Optimizations:
- Sophisticated all-reduce algorithms for gradient synchronization
- Pipeline parallelism for efficient multi-device utilization
- ZeRO-style optimizer state sharding
- Communication overlap with computation to maximize throughput
- Training Stability Techniques:
- Gradient clipping to prevent exploding gradients
- Carefully tuned weight initialization strategies
- Normalization technique selection and hyperparameter tuning
- Potentially progressive layer freezing during fine-tuning
- Convergence Acceleration:
- Adaptive optimization algorithms (likely AdamW variants)
- Potential use of curriculum learning strategies
- Specialized scheduling for different training phases
- Transfer learning from previous model iterations
These optimization techniques collectively enabled efficient training of a model with hundreds of billions of parameters while maintaining numerical stability and convergence quality.
Fine-tuning Process
The specialized fine-tuning process is crucial for developing Grok's distinctive capabilities:
- Instruction Tuning:
- Training on diverse instruction-response pairs
- Coverage of common user request types
- Special emphasis on complex reasoning instructions
- Balanced representation of creative, analytical, and factual tasks
- Safety Alignment:
- Training to identify and refuse potentially harmful requests
- Development of balanced responses to controversial topics
- Implementation of xAI's "maximum truth-seeking" philosophy
- Calibration of response boundaries reflecting xAI's approach to safety
- Conversation Calibration:
- Fine-tuning on multi-turn conversations
- Development of contextual awareness across exchanges
- Training on effective clarification and follow-up patterns
- Personality calibration to develop the "rebellious" character
- Web Browsing Integration:
- Specialized training for determining when to use web access
- Query formulation optimization for effective search
- Training on information extraction from diverse web pages
- Source integration and synthesis with model knowledge
- Technical Capability Enhancement:
- Focused training on reasoning tasks and logical problems
- Code generation and understanding specialization
- Mathematical problem-solving capability development
- Technical documentation and explanation quality enhancement
The fine-tuning process likely involved multiple iterations with evaluation on specialized benchmarks to track progress across different capability dimensions.
Technical Comparison
Grok's training methodology can be distinguished from other leading LLMs in several ways:
- Comparison with OpenAI (GPT) Approach:
- Similar fundamental pre-training methodology
- Potentially different emphasis in safety alignment reflecting xAI's philosophy
- Likely more integrated approach to real-time information access vs. OpenAI's plugin system
- Potentially different balance in RLHF reward functions reflecting different values
- Comparison with Anthropic (Claude) Approach:
- Both use RLHF, but likely with different reward signals reflecting different company values
- Anthropic's Constitutional AI approach vs. xAI's "truth-seeking" orientation
- Different approaches to context window scaling (Claude pursuing much larger windows)
- Different emphasis on web access integration
- Comparison with Google (PaLM/Gemini) Approach:
- Similar scale but potentially different architectural choices
- Google's potential advantage in proprietary training data
- Different approaches to multimodal training (Google's models designed as multimodal from inception)
- Different optimization techniques leveraging company-specific expertise
- xAI Distinctive Elements:
- Potentially different data filtering criteria reflecting xAI's stated values
- More emphasis on real-time information access as a core capability
- "Rebellious" personality development as an explicit training goal
- Potentially different political bias mitigation approaches
These training methodology differences, while sometimes subtle, contribute to the distinctive capabilities and characteristics that differentiate Grok from its competitors in the LLM landscape.
Performance Benchmarks
Understanding Grok AI's capabilities requires examination of its performance across standardized benchmarks and real-world tasks. This section analyzes Grok's performance profile based on available benchmark data and comparative analysis.
Standardized Tests
Grok has been evaluated on several standard LLM benchmarks, with performance that places it among competitive high-tier models:
- MMLU (Massive Multitask Language Understanding):
- Estimated score: 76-80% (Grok-1.5)
- This places Grok in the upper tier of models, though slightly behind the top performers like GPT-4 (86-89%) and Claude 3 Opus (86-89%)
- Particular strength in STEM categories, with somewhat lower performance in humanities subjects
- Notable improvement from Grok-1 to Grok-1.5, suggesting effective optimization for reasoning capabilities
- HumanEval (Programming Benchmark):
- Estimated score: 65-70% (Grok-1.5)
- Competitive but not field-leading performance for code generation
- Strong performance on Python tasks, with gradually declining performance on less common languages
- Notable capability in algorithm implementation and debugging tasks
- GSM8K (Grade School Math):
- Estimated score: 75-80% (Grok-1.5)
- Significant improvement from Grok-1, suggesting enhanced reasoning capabilities
- Performance indicates strong step-by-step reasoning ability
- Remaining errors typically occur in problems requiring complex multi-step reasoning
- TruthfulQA:
- Estimated score: 60-65% (Grok-1.5)
- Moderate performance on factual accuracy assessment
- Balance between truthfulness and information coverage reflects xAI's approach
- Performance suggests effective mitigation of common hallucination patterns
- BIG-Bench Hard:
- Performance varies significantly across subtasks
- Strong performance on logical reasoning components
- Moderate performance on tasks requiring specialized world knowledge
- Above-average performance on linguistic understanding tasks
- HELM Benchmark Suite:
- Competitive performance across multiple dimensions
- Strong scores on helpfulness metrics
- Above-average performance on harmlessness metrics
- Moderate performance on honesty metrics, reflecting xAI's particular alignment approach
These standardized benchmark results position Grok among the more capable general-purpose LLMs, though typically slightly behind the very top performers in most categories. The benchmarks show particularly strong performance in reasoning-intensive tasks, which aligns with xAI's stated development priorities.
Comparative Analysis
When compared directly with other leading LLMs, Grok shows a distinctive performance profile:
- Comparison with GPT-4:
- GPT-4 generally outperforms Grok on most standardized benchmarks by a modest margin (typically 5-10%)
- Grok shows competitive performance on reasoning-focused tasks, approaching GPT-4's capabilities
- Grok's real-time information access provides an advantage for current events, potentially outperforming GPT-4 on questions requiring post-training-cutoff information
- GPT-4 demonstrates stronger performance on creative writing and nuanced ethical reasoning
- Comparison with Claude 3 Models:
- Claude 3 Opus outperforms Grok on most benchmarks, with particularly strong advantages in reasoning tasks
- Claude 3 Sonnet performs similarly to Grok overall, with different strengths in specific domains
- Claude models generally show stronger performance on tasks requiring nuanced understanding of human values
- Grok's "rebellious" personality creates different interaction patterns that aren't fully captured in standard benchmarks
- Comparison with Gemini Models:
- Gemini Ultra outperforms Grok on most multimodal tasks
- Gemini Pro performs comparably to Grok on text-only tasks
- Grok and Gemini models take different approaches to real-time information access
- Performance differences vary significantly by task type and domain
- Comparison with Open Models (Llama, Mistral):
- Grok outperforms most open-source models across benchmark categories
- The performance gap is narrowing with newer open model releases
- Some specialized open models outperform Grok in specific domains
- Grok's web browsing capabilities provide advantages not present in most open models
This comparative analysis reveals Grok's position in the competitive landscape: a capable general-purpose model with particular strengths in reasoning and real-time information access, though not consistently field-leading across all benchmarks.
Real-world Performance
Beyond standardized benchmarks, Grok's real-world performance demonstrates several notable characteristics:
- Conversational Interaction:
- Strong performance in maintaining context across multiple turns
- Distinctive conversational style reflecting the "rebellious" personality
- Effective handling of clarification requests and ambiguous queries
- Occasional inconsistency in very long conversations approaching context window limits
- Knowledge Tasks:
- Excellent performance on knowledge questions within training data scope
- Strong capability in leveraging web access for current information
- Occasional challenges with obscure domain-specific knowledge
- Variable performance depending on search result quality for web-dependent queries
- Reasoning and Problem-Solving:
- Strong performance on straightforward logical reasoning tasks
- Declining performance as reasoning chains become longer or more complex
- Effective step-by-step problem decomposition for moderately complex problems
- Occasional reasoning errors in highly complex scenarios
- Content Generation:
- High-quality output for standard creative and professional content tasks
- Strong performance in adapting to specified tones and styles
- Occasional repetition or structure issues in very long-form content
- Distinctive creative voice that reflects training and alignment approach
- Technical Tasks:
- Solid code generation for common programming tasks
- Effective technical explanation with appropriate detail levels
- Strong performance in API documentation and technical writing
- Variable performance in highly specialized technical domains
- Multimodal Capabilities (Grok-1.5V):
- Effective basic image understanding and description
- Appropriate integration of visual information in responses
- Limited performance on complex visual reasoning compared to specialized multimodal models
- Strong text-primary multimodal interactions where images provide context
These real-world performance characteristics paint a picture of a versatile assistant with strong general capabilities and particular effectiveness in information-intensive tasks that benefit from real-time data access.
Data Visualization

Figure 2: Radar chart comparing Grok-1.5 performance against other leading LLMs across key benchmark categories. The visualization illustrates Grok's competitive positioning, with particular strength in reasoning and real-time knowledge access.
Analysis Methodology
Understanding benchmark results requires appreciation of how these evaluations are conducted:
- Benchmark Construction Considerations:
- Most standardized benchmarks evaluate specific capability dimensions in isolation
- Many benchmarks favor models with extensive knowledge incorporated during training
- Few benchmarks effectively measure real-time information access capabilities
- Benchmark construction often reflects the priorities and values of their creators
- Evaluation Approaches:
- Direct model output evaluation for objective tasks (e.g., mathematics, code execution)
- Human evaluation for subjective quality assessment
- Reference-based evaluation comparing outputs to "gold standard" answers
- Ranked comparison between models for relative performance assessment
- Benchmark Limitations:
- Limited coverage of real-world use cases and contexts
- Potential for benchmark-specific optimization during training
- Challenges in evaluating distinctive features like personality or style
- Difficulty measuring important practical characteristics like reliability
- Holistic Evaluation Framework:
- Complementing standardized benchmarks with real-world task evaluation
- Assessing performance across diverse domains and complexity levels
- Evaluating consistency and reliability rather than just peak performance
- Considering alignment with specific organizational needs and use cases
This nuanced approach to performance analysis provides a more complete picture of Grok's capabilities than any single benchmark score, recognizing both its competitive strengths and the areas where other models may offer advantages for specific applications.
Real-time Information Access
One of Grok AI's most distinctive technical features is its ability to access and process information from the internet in real-time. This capability represents a significant engineering achievement that addresses the knowledge cutoff limitation affecting many LLMs.
Technical Implementation
Grok's real-time information access capability is implemented through a sophisticated system architecture that integrates several components:
- Query Analysis Subsystem:
- Intent Classification: Specialized neural networks determine whether a query would benefit from real-time information access.
- Knowledge Gap Detection: Algorithms identify when questions likely fall outside the model's training data (e.g., recent events, rapidly changing topics).
- Query Type Classification: Different processing for factual queries, trend analysis, comparison requests, etc.
- Search Query Formulation:
- Query Transformation: Neural mechanisms convert natural language questions into effective search queries.
- Parameter Optimization: Automatic adjustment of search parameters based on query type.
- Multi-query Planning: For complex questions, sequential or parallel query strategies are developed.
- Search Execution Engine:
- API Integration: Secure connections to search engine APIs with appropriate authentication.
- Rate Limiting Management: Systems to ensure responsible API usage within rate constraints.
- Result Retrieval: Efficient processing of search engine responses with error handling.
- Content Access System:
- Source Selection: Algorithms to identify the most promising sources from search results.
- Content Retrieval: Systems for accessing and downloading web content.
- Content Parsing: Specialized parsers for extracting relevant information from various document formats and structures.
- Error Handling: Robust mechanisms for handling access failures, timeouts, or content restrictions.
- Integration with Core Model:
- Context Window Management: Efficient allocation of context space for web content.
- Web Content Representation: Preprocessing to transform web content into optimal token representations.
- Integration Signaling: Special tokens or embeddings that indicate externally sourced information.
This technical architecture enables Grok to seamlessly incorporate real-time information while maintaining a coherent user experience, distinguishing it from systems that require explicit plugin activation or separate tools for external information access.
Knowledge Retrieval Mechanisms
The process of gathering and utilizing external information involves several sophisticated mechanisms:
- Information Source Selection:
- Source Credibility Assessment: Algorithms that evaluate the reliability of potential sources based on various signals.
- Relevance Ranking: Systems for prioritizing sources most likely to contain information relevant to the specific query.
- Diversity Consideration: Mechanisms to ensure consideration of multiple perspectives when appropriate.
- Recency Weighting: Prioritization of recently updated sources for time-sensitive topics.
- Content Extraction Techniques:
- Main Content Identification: Algorithms to distinguish primary content from navigation, ads, and other peripheral elements.
- Structured Data Extraction: Specialized parsing for tables, lists, and other structured information.
- Entity Recognition: Identification of key entities, dates, statistics, and relationships within content.
- Cross-document Coreference: Mechanisms to identify when different sources discuss the same entities or events.
- Hierarchical Processing:
- Two-phase Retrieval: Initial broad search followed by focused content extraction from promising sources.
- Progressive Refinement: Iterative improvement of information gathering based on initial results.
- Depth Adjustment: Dynamic determination of how deeply to analyze sources based on query complexity.
- Multi-source Information Integration:
- Consistency Analysis: Identification of agreements and contradictions across sources.
- Information Fusion: Techniques for combining complementary information from multiple sources.
- Uncertainty Propagation: Methods for representing confidence levels based on source quality and consensus.
These knowledge retrieval mechanisms enable Grok to effectively gather relevant, current information while managing the challenges of web content diversity, quality variation, and information conflicts.
Information Synthesis
Once information is retrieved, Grok employs sophisticated processes to synthesize it into coherent, useful responses:
- Information Integration Framework:
- Knowledge Graph Construction: Building temporary structured representations of retrieved information.
- Parametric Knowledge Augmentation: Combining retrieved information with the model's existing knowledge.
- Temporal Contextualization: Placing information correctly in time, especially for evolving topics.
- Hierarchical Representation: Organizing information at different levels of detail and abstraction.
- Reasoning Processes:
- Inductive Synthesis: Drawing reasonable conclusions from multiple information points.
- Contradiction Resolution: Approaches for handling conflicting information from different sources.
- Uncertainty Handling: Appropriate expression of confidence levels in synthesized information.
- Knowledge Gap Identification: Recognition of what remains unknown despite information retrieval.
- Response Generation Strategy:
- Information Selection: Choosing which retrieved details to include based on relevance and confidence.
- Structure Determination: Organizing information logically for presentation.
- Attribution Integration: Incorporating source information appropriately.
- Language Adaptation: Reformulating information into natural language while preserving accuracy.
- Quality Enhancement:
- Fact Verification: Cross-checking important claims across multiple sources when possible.
- Coherence Optimization: Ensuring logical flow and consistency in synthesized information.
- Detail Calibration: Determining appropriate specificity based on query needs and information reliability.
- Bias Mitigation: Techniques to recognize and address potential biases in source material.
These synthesis processes enable Grok to transform raw web information into valuable, coherent responses that effectively address user queries while maintaining appropriate standards for accuracy and relevance.
Limitations and Constraints
Despite its sophisticated implementation, Grok's real-time information access capability operates within several technical boundaries:
- Search Engine Limitations:
- Index Latency: Search engines typically have hours to days of latency for indexing new content.
- Coverage Boundaries: Not all web content is indexed by search engines, creating blind spots.
- Ranking Biases: Search algorithms have inherent biases that affect which information is surfaced.
- Query Formulation Sensitivity: Results can vary dramatically based on subtle query differences.
- Content Access Constraints:
- Paywall Restrictions: Inability to access content behind paywalls or login requirements.
- Format Limitations: Challenges processing certain complex document formats or heavily JavaScript-dependent sites.
- Rate Limitations: Practical constraints on how many distinct sources can be accessed per query.
- Robots.txt Compliance: Ethical and legal requirements to respect site access restrictions.
- Information Processing Challenges:
- Context Window Constraints: Limited space to include retrieved information alongside query and conversation history.
- Temporal Ambiguity: Difficulties determining precise publication dates for some content.
- Source Evaluation Complexity: Inherent challenges in programmatically assessing source credibility.
- Deep Specialization: Limitations in evaluating highly specialized technical or scientific content.
- Response Generation Boundaries:
- Synthesis Complexity: Challenges in integrating information with many contradictions or nuances.
- Attribution Tradeoffs: Balancing comprehensive attribution with response readability.
- Uncertainty Communication: Difficulties in effectively expressing confidence levels to users.
- Response Time Impacts: Latency introduced by external information access and processing.
Understanding these constraints is essential for effective implementation planning, as they define the boundaries of what Grok's real-time information access can realistically achieve despite its sophisticated architecture.
Security Architecture
The integration of external information access introduces specific security considerations that Grok's architecture must address:
- Query Security:
- Query Sanitization: Mechanisms to prevent injection attacks or manipulation of search systems.
- Information Leakage Prevention: Controls ensuring that sensitive conversation details aren't included in search queries.
- Authentication Security: Secure management of credentials for search API access.
- Query Logging: Appropriate privacy-preserving logging for security monitoring.
- Content Processing Security:
- Content Isolation: Technical boundaries preventing retrieved web content from affecting system behavior beyond intended information extraction.
- Dangerous Content Detection: Scanning mechanisms to identify potentially malicious content.
- Rendering Sandbox: Isolated environments for processing web content to prevent security vulnerabilities.
- File Type Restrictions: Limitations on what types of content can be accessed and processed.
- Information Flow Controls:
- Data Provenance Tracking: Maintaining clear boundaries between model knowledge and externally sourced information.
- Permission Boundaries: Controls on what external resources can be accessed.
- Information Handling Policies: Clear guidelines for processing and storing retrieved information.
- Privacy Protection: Mechanisms ensuring user privacy throughout the information access process.
- Response Security:
- Source Validation: Verification that information comes from legitimate sources before inclusion.
- Attribution Accuracy: Systems ensuring correct attribution of externally sourced information.
- Harmful Content Filtering: Multiple layers of review to prevent propagation of harmful content from external sources.
- User Safety Prioritization: Override mechanisms that block potentially dangerous information regardless of source.
These security mechanisms are essential for maintaining the integrity, privacy, and safety of Grok's real-time information access capabilities, ensuring that this powerful feature enhances user experience without introducing unacceptable risks.
Inference and Response Generation
Understanding how Grok processes queries and generates responses requires examining the sophisticated inference pipeline that transforms user inputs into coherent, contextually appropriate outputs.
Inference Engine Analysis
Grok's inference engine represents a complex system for processing inputs and generating meaningful responses:
- Input Processing Pipeline:
- Tokenization: Conversion of raw text input into token sequences using Grok's vocabulary.
- Embedding Generation: Transformation of tokens into high-dimensional vector representations.
- Context Integration: Merging new input with conversation history in the context window.
- Intent Analysis: Classification of query type, domain, and specific request characteristics.
- Transformer Processing:
- Self-attention Computation: Calculation of attention patterns across the entire context.
- Layer-by-layer Processing: Sequential transformation through multiple transformer layers.
- Representation Refinement: Progressive enhancement of token representations through the network.
- Feature Extraction: Development of increasingly abstract and contextual features through depth.
- Knowledge Access Mechanisms:
- Internal Knowledge Activation: Retrieval of relevant information from model parameters.
- External Knowledge Decision: Determination of when to activate web browsing capabilities.
- Knowledge Integration: Combining parametric and external knowledge when appropriate.
- Uncertainty Assessment: Evaluation of confidence in available information.
- Reasoning Process:
- Logical Analysis: Application of reasoning patterns to problem-solving tasks.
- Multi-step Reasoning: Management of extended reasoning chains for complex queries.
- Inference Generation: Drawing appropriate conclusions from available information.
- Self-consistency Checking: Verification of logical coherence in developing responses.
These inference engine components work together to process inputs comprehensively, accessing relevant knowledge and applying appropriate reasoning patterns before generating responses.
Response Construction
Grok employs sophisticated approaches to constructing responses that effectively address user queries:
- Generation Strategy Selection:
- Response Type Determination: Selection of appropriate response approach based on query type.
- Structure Planning: Development of logical response organization for complex answers.
- Detail Calibration: Determination of appropriate specificity and comprehensiveness.
- Style Selection: Adjustment of tone and formality based on context and query characteristics.
- Autoregressive Generation Process:
- Token Prediction: Sequential prediction of each output token based on all previous tokens.
- Next-token Distribution: Calculation of probability distributions over possible next tokens.
- Sampling Strategy: Application of techniques like temperature sampling, top-p, or similar approaches.
- Stopping Criteria: Determination of appropriate response completion points.
- Content Organization Techniques:
- Information Prioritization: Presenting most important information first in most contexts.
- Logical Sequencing: Arranging information in coherent, logical progressions.
- Hierarchical Structuring: Using appropriate headings, lists, and paragraphing for clarity.
- Transitional Elements: Including appropriate connections between response components.
- Output Refinement:
- Coherence Optimization: Ensuring logical flow and consistency throughout responses.
- Clarity Enhancement: Avoiding ambiguity and providing appropriate detail.
- Brevity Balancing: Providing comprehensive information without unnecessary verbosity.
- Style Consistency: Maintaining consistent tone and approach throughout responses.
These response construction mechanisms enable Grok to generate outputs that effectively address user queries while maintaining coherence, accuracy, and appropriate style.
Contextual Management
Maintaining coherent conversations across multiple turns requires sophisticated context management:
- Context Window Utilization:
- Token Budget Allocation: Strategic distribution of limited context space across conversation history.
- Compression Techniques: Methods for maintaining essential information while reducing token usage.
- Recency Biasing: Prioritizing recent exchanges while maintaining awareness of earlier context.
- Critical Information Preservation: Ensuring key facts and user preferences remain accessible.
- Reference Resolution:
- Entity Tracking: Maintaining representations of entities mentioned throughout conversation.
- Pronoun Resolution: Connecting pronouns to their appropriate antecedents.
- Implicit Reference Handling: Resolving references that lack explicit antecedents.
- Topic Continuity: Tracking conversation topics across multiple exchanges.
- Memory Management:
- Short-term Contextual Memory: Immediate conversation history in the context window.
- Information Summarization: Techniques for condensing important information from longer exchanges.
- Priority Determination: Systems for determining which context elements to preserve when space is limited.
- Context Refresh Strategies: Approaches for reestablishing important context when needed.
- Conversation Flow Optimization:
- Topic Transition Handling: Maintaining coherence during topic shifts.
- Contextual Return: Appropriately returning to previous topics when relevant.
- Consistency Enforcement: Ensuring responses remain consistent with established information.
- Clarification Integration: Incorporating user clarifications into evolving context.
These contextual management mechanisms enable Grok to maintain coherent, natural conversations that build upon previous exchanges while working within the constraints of finite context windows.
Optimization Techniques
Grok employs various techniques to optimize inference and response generation:
- Computational Efficiency Optimizations:
- Key-Value Caching: Reusing attention key-value pairs from previous generation steps.
- Attention Optimizations: Specialized algorithms for more efficient attention computation.
- Quantization: Potential use of lower precision calculations for inference efficiency.
- Speculative Decoding: Potentially predicting multiple tokens simultaneously to increase throughput.
- Latency Reduction Approaches:
- Parallel Processing: Utilizing multiple processing units simultaneously where possible.
- Batch Processing: Efficient handling of computation across multiple requests.
- Inference Pipeline Optimization: Minimizing overhead between processing stages.
- Priority-based Resource Allocation: Directing computing resources based on query complexity and urgency.
- Output Quality Enhancements:
- Re-ranking: Potentially evaluating multiple candidate responses and selecting the best.
- Self-consistency Checking: Verifying logical consistency in developing responses.
- Factuality Verification: Cross-checking factual claims when possible.
- Coherence Optimization: Ensuring logical flow throughout extended responses.
- Specialized Processing Paths:
- Task-specific Optimizations: Customized processing for different query types.
- Multi-stage Generation: Breaking complex responses into planned segments.
- Hybrid Approaches: Combining different generation strategies for optimal results.
- Adaptive Computation: Varying processing depth based on query complexity.
These optimization techniques balance computational efficiency with response quality, enabling Grok to provide high-quality outputs while maintaining reasonable response times across diverse query types.
API Request/Response Patterns
While detailed API documentation for Grok is not yet publicly available, likely API patterns can be inferred based on industry standards and xAI's approach:
// Example API Request
{
"messages": [
{"role": "user", "content": "What are the latest developments in quantum computing?"}
],
"model": "grok-1.5",
"max_tokens": 1000,
"temperature": 0.7,
"web_access": true,
"stream": false
}
// Example API Response
{
"id": "resp_8f7d3e2a1b5c",
"object": "completion",
"created": 1715012345,
"model": "grok-1.5",
"web_access_used": true,
"message": {
"role": "assistant",
"content": "As of May 2025, there have been several significant developments in quantum computing:\n\n1. **IBM's New Quantum Processor**: IBM recently announced their newest quantum processor with improved error correction, reaching over 1,000 qubits while substantially reducing error rates.\n\n2. **Quantum Advantage Demonstration**: Researchers at Google published results demonstrating quantum advantage in a new class of chemical simulation problems, showing clear superiority over classical approaches.\n\n[Additional content...]",
"sources": [
{
"url": "https://research.ibm.com/blog/new-quantum-processor-2025",
"title": "IBM Announces Next-Generation Quantum Processor",
"access_time": "2025-05-10T14:32:10Z"
},
{
"url": "https://ai.googleblog.com/2025/04/quantum-advantage-chemical-simulation",
"title": "Demonstrating Quantum Advantage in Chemical Simulation Tasks",
"access_time": "2025-05-10T14:32:15Z"
}
]
},
"usage": {
"prompt_tokens": 10,
"completion_tokens": 420,
"total_tokens": 430
}
}
This hypothetical API pattern illustrates several likely characteristics:
- Conversation-oriented Structure:
- Message-based format similar to other LLM APIs
- Support for multi-turn conversations through message arrays
- Clear role delineation between user and assistant
- Control Parameters:
- Standard generation parameters like temperature and max_tokens
- Specific flags for capabilities like web access
- Potential streaming support for progressive response delivery
- Information Attribution:
- Structured source information when web access is used
- Clear timestamps for when information was accessed
- Links to original sources for verification
- Usage Tracking:
- Token counting for both input and output
- Potential tracking of specific feature usage (e.g., web access)
- Information to support usage-based billing models
While the actual API implementation may differ in specific details, this pattern represents a likely approach based on industry standards and the specific capabilities of Grok.
Hardware Requirements and Scalability
Deploying and scaling Grok AI effectively requires understanding its hardware requirements, resource utilization patterns, and scalability characteristics.
Deployment Requirements
The hardware infrastructure needed to run Grok effectively varies based on deployment scale and performance requirements:
- Minimum Viable Deployment:
- GPU Requirements: High-end NVIDIA GPUs (A100, H100, or equivalent) with 40-80GB VRAM
- CPU Specifications: High-performance server-grade CPUs with multiple cores
- Memory Requirements: 128GB+ RAM for supporting processes
- Storage Needs: SSD storage with high I/O capabilities for model weights and caching
- Network Infrastructure: High-bandwidth, low-latency networking for distributed components
- Production-Scale Deployment:
- GPU Clusters: Multiple interconnected high-end GPUs with NVLink or similar high-speed connections
- Distributed Processing: Load balancing across multiple servers
- Memory Architecture: Tiered memory system with high-speed access for active components
- Storage Architecture: Distributed storage system with caching layers
- Network Requirements: Dedicated high-speed interconnects between components
- Enterprise Deployment Considerations:
- Redundancy Requirements: N+1 or N+2 hardware redundancy for production reliability
- Geographical Distribution: Potential for multi-region deployment for latency optimization
- Scaling Infrastructure: Auto-scaling capabilities for variable load management
- Monitoring Systems: Comprehensive hardware and performance monitoring
- Backup Infrastructure: Appropriate backup systems for configuration and data
- Cloud vs. On-Premises Considerations:
- Cloud Advantages: Simplified scaling, managed infrastructure, potentially lower upfront costs
- On-Premises Advantages: Potentially better data control, customization flexibility, potential long-term cost benefits
- Hybrid Approaches: Combined deployments leveraging advantages of both models
- Specialized Cloud Offerings: Potential for optimized cloud configurations from providers
These deployment requirements represent significant infrastructure investments, particularly for large-scale implementations, explaining why many organizations access Grok and similar models through hosted services rather than self-hosting.
Scaling Characteristics
Grok exhibits several important scaling patterns that affect deployment planning:
- Vertical Scaling Properties:
- GPU Memory Scaling: Performance improvements with higher VRAM up to model size requirements
- GPU Computation Scaling: Near-linear performance scaling with increased GPU computational capacity
- Latency Optimization: Diminishing returns beyond certain hardware thresholds
- Single-instance Limits: Maximum performance ceiling for single-server deployments
- Horizontal Scaling Properties:
- Request Distribution: Effective scaling through load distribution across multiple servers
- Stateless Processing: Ability to route requests to any available processing node
- Scaling Linearity: Near-linear capacity scaling with additional processing nodes
- Infrastructure Overhead: Increasing coordination overhead at very large scales
- Load Characteristics:
- Query Complexity Variation: Wide variance in resource requirements based on query complexity
- Batch Processing Efficiency: Significant throughput improvements through batching
- Throughput vs. Latency Tradeoffs: Balancing decisions between response time and total processing capacity
- Bursty Traffic Patterns: Typical user interaction patterns creating variable load profiles
- Scaling Strategies:
- Query Routing: Intelligent distribution based on query characteristics
- Specialized Processing Paths: Dedicated resources for different query types
- Capacity Planning: Balancing provisioning against actual usage patterns
- Dynamic Resource Allocation: Adapting resource assignment based on real-time demands
Understanding these scaling characteristics enables organizations to develop effective capacity planning and deployment strategies that balance performance requirements with infrastructure costs.
Resource Utilization
Grok's operation involves distinctive resource utilization patterns that affect infrastructure planning:
- Computational Resource Utilization:
- GPU Utilization: Heavy utilization during both input processing and token generation
- Memory Access Patterns: High-bandwidth memory access for model weights and activations
- CPU Utilization: Moderate usage for pre/post-processing and coordination
- Accelerator-specific Optimizations: Potential specialized usage of tensor cores or similar hardware
- Memory Usage Patterns:
- Model Weight Storage: Substantial memory requirements for model parameters
- KV Cache Scaling: Memory usage scaling with context length and batch size
- Working Memory Requirements: Additional memory needed for intermediate calculations
- Buffer Allocations: Memory overhead for input/output processing
- Bandwidth Requirements:
- Internal Data Movement: High bandwidth needs between memory and computation units
- External Communication: Moderate bandwidth for API communication
- Web Access Overhead: Additional bandwidth requirements for real-time information access
- Distributed Communication: Inter-node communication for distributed deployments
- Utilization Variations:
- Query-dependent Fluctuations: Resource needs varying significantly based on query complexity
- Context Length Impact: Resources scaling with conversation length
- Feature-specific Overhead: Additional resources required for capabilities like web browsing
- Throughput Optimization: Efficiency gains through appropriate batching and scheduling
These resource utilization patterns highlight the importance of appropriate hardware selection and configuration for efficient Grok deployment, with particular emphasis on GPU capabilities, memory architecture, and inter-component bandwidth.
Optimization Opportunities
Several optimization approaches can enhance performance and efficiency in Grok deployments:
- Hardware-level Optimizations:
- GPU Selection: Choosing optimal GPU architectures for inference workloads
- Memory Configuration: Optimizing memory hierarchies for model access patterns
- Interconnect Optimization: High-bandwidth, low-latency connections between components
- Storage Tiering: Strategic data placement across storage hierarchy
- Model Optimization Techniques:
- Quantization: Reducing precision requirements through techniques like INT8/FP16 quantization
- Pruning: Potential selective pruning of model weights with minimal accuracy impact
- Distillation: Possibly creating smaller, specialized versions for specific use cases
- Caching Strategies: Efficient reuse of computation results when appropriate
- Inference Pipeline Optimizations:
- Batching Enhancement: Intelligent request batching for throughput improvement
- Parallel Processing: Optimizing concurrent request handling
- Pipeline Parallelism: Efficient distribution of model across multiple devices
- Request Prioritization: Intelligent scheduling based on complexity and urgency
- Deployment Architecture Optimizations:
- Load Balancing Refinement: Intelligent request routing based on real-time resource availability
- Caching Layers: Strategic caching of common responses for frequently asked questions
- Geographical Distribution: Placement optimization based on user distribution
- Hybrid Processing: Combining cloud and edge processing for optimal efficiency
These optimization opportunities offer significant potential for improving performance, reducing costs, and enhancing user experience in Grok deployments, particularly at larger scales where efficiency gains have substantial impact.
Enterprise Considerations
Organizations implementing Grok at enterprise scale face several important technical considerations:
- High Availability Architecture:
- Redundancy Requirements: N+1 or N+2 system design for critical components
- Failure Domain Isolation: Containing failures to minimize service impact
- Automated Failover: Seamless transition to backup systems when needed
- Disaster Recovery: Comprehensive planning for major outage scenarios
- Performance Management:
- SLA Definition: Establishing appropriate performance expectations
- Capacity Planning: Ensuring sufficient resources for peak demands
- Performance Monitoring: Real-time tracking of key performance indicators
- Scaling Triggers: Defining appropriate thresholds for resource expansion
- Cost Optimization:
- Resource Right-sizing: Matching provisioned resources to actual requirements
- Usage-based Scaling: Adjusting capacity based on demand patterns
- Deployment Model Selection: Choosing optimal combination of cloud/on-premises resources
- Efficiency Metrics: Tracking cost-per-inference and similar efficiency measures
- Integration Requirements:
- Authentication Systems: Secure integration with enterprise identity management
- Monitoring Infrastructure: Connection with organizational monitoring systems
- Logging Framework: Compliance with enterprise logging standards
- Management Tools: Integration with existing IT management systems
- Compliance Considerations:
- Data Residency: Addressing geographic restrictions on data processing
- Audit Capabilities: Supporting required logging and auditing functions
- Security Standards: Meeting organizational and regulatory security requirements
- Privacy Controls: Implementing appropriate data protection measures
These enterprise considerations highlight the additional complexity involved in large-scale organizational deployments beyond the core technical requirements, emphasizing the importance of comprehensive planning that addresses both technical and operational dimensions.
Technical Integration Capabilities
Effectively leveraging Grok AI in enterprise environments requires understanding its integration capabilities, protocols, and security mechanisms.
API Architecture
Grok's API architecture likely follows modern design principles while incorporating specialized elements for its unique capabilities:
- API Design Philosophy:
- RESTful Design: Following REST principles for resource-oriented interactions
- Stateless Core: Maintaining statelessness for scalability while supporting conversational context
- Versioning Strategy: Clear versioning to support API evolution without breaking existing integrations
- Consistency Principles: Uniform patterns across different endpoints and functions
- Core Endpoints and Functions:
- Conversation Endpoint: Primary interface for interactive conversations
- Completion Endpoint: Potentially separate endpoint for single-turn completions
- Stream Endpoint: Real-time response streaming for progressive display
- Files Endpoint: Management of associated documents or files
- Model Information Endpoint: Details about available models and capabilities
- Parameter Structure:
- Generation Parameters: Controls for response characteristics (temperature, max_tokens, etc.)
- Feature Flags: Toggles for capabilities like web browsing
- Context Management: Mechanisms for handling conversation history
- Response Formatting: Options for controlling output structure and format
- Error Handling Framework:
- Standardized Error Codes: Consistent error categorization
- Detailed Error Messages: Informative descriptions for troubleshooting
- Graceful Degradation: Fallback behaviors for partial failures
- Rate Limiting Signals: Clear communication about usage limits
- Developer Experience Considerations:
- Comprehensive Documentation: Clear explanations with examples
- Client Libraries: Potentially language-specific SDKs for common platforms
- Playground Environment: Interactive testing capabilities
- Request/Response Logging: Debugging tools for integration development
This API architecture provides the foundation for technical integration, enabling developers to effectively incorporate Grok's capabilities into applications, services, and business processes.
Integration Protocols
Grok supports several approaches for integration with existing systems and workflows:
- Communication Protocols:
- HTTPS: Primary protocol for secure API communication
- WebSockets: Potential support for real-time bidirectional communication
- gRPC: Possible support for high-performance streaming interactions
- Webhook Callbacks: Potential asynchronous notification mechanisms
- Authentication Methods:
- API Key Authentication: Simple authentication using assigned keys
- OAuth 2.0: Potential support for delegated authentication flows
- JWT Authentication: Token-based authentication with claims support
- Enterprise SSO Integration: Possible support for organizational identity systems
- Interaction Patterns:
- Synchronous Request-Response: Standard immediate response pattern
- Streaming Response: Progressive response delivery for longer outputs
- Asynchronous Processing: Submission and later retrieval for complex tasks
- Batch Processing: Handling multiple requests efficiently in batch mode
- Application Integration Approaches:
- Direct API Integration: Custom code directly calling Grok APIs
- Middleware Approach: Using intermediate layers for enhanced control
- Serverless Functions: Lightweight integration via cloud functions
- Message Queue Integration: Decoupled processing via message queues
- Enterprise Platform Connectivity:
- CRM Integration: Connection with customer relationship management systems
- Support System Integration: Enhancing customer support platforms
- Knowledge Base Connectivity: Augmenting existing knowledge management systems
- Workflow System Integration: Embedding within business process flows
These integration protocols provide flexible options for connecting Grok with various systems and services, enabling organizations to incorporate its capabilities into diverse technical environments.
Data Exchange Formats
Effective integration requires understanding the formats used for data exchange with Grok:
- Request/Response Formats:
- JSON Structure: Primary format for API communication
- UTF-8 Encoding: Standard encoding for text content
- Binary Data Handling: Approaches for non-text content when relevant
- Content-Type Standards: Clear specification of data types
- Conversation Format:
- Message-based Structure: Organized as sequences of messages with roles
- Role Delineation: Clear identification of user vs. system messages
- Metadata Support: Additional information beyond core message content
- Formatting Preservation: Handling of structured content within messages
- Special Data Types:
- Function Call Representation: Format for representing tool usage or function calls
- Web Browsing Results: Structure for presenting web-sourced information
- Source Attribution: Format for representing information sources
- Multimodal Content: Representation of image and potentially other non-text content
- Schema Definition:
- OpenAPI/Swagger Documentation: Formal API definition
- JSON Schema: Detailed structure definition for request/response formats
- Validation Rules: Clear specification of required vs. optional fields
- Extensibility Patterns: Approaches for handling format evolution
- Special Considerations:
- Large Payload Handling: Approaches for managing substantial response sizes
- Streaming Format: Structure for incremental response delivery
- Error Representation: Consistent format for error communication
- Versioning Indicators: Clear marking of format versions
Understanding these data exchange formats is essential for successful integration, ensuring proper communication between Grok and other systems while maintaining data integrity and compatibility.
Authentication Mechanisms
Secure integration with Grok requires appropriate authentication and authorization mechanisms:
- API Key Management:
- Key Generation: Secure processes for creating and distributing API keys
- Scope Limitation: Ability to restrict keys to specific capabilities
- Rotation Policies: Recommended practices for periodic key rotation
- Revocation Mechanisms: Processes for immediate key invalidation when needed
- Identity Integration:
- Organization Identity Mapping: Connection with enterprise identity systems
- Role-based Authorization: Access control based on organizational roles
- Single Sign-On Support: Integration with enterprise SSO solutions
- Identity Federation: Support for multi-organization identity frameworks
- Security Token Approaches:
- JWT Implementation: Using JSON Web Tokens for secure authentication
- Token Lifecycle: Creation, validation, and expiration management
- Claims Processing: Leveraging token claims for authorization decisions
- Refresh Mechanisms: Secure approaches for extending authentication sessions
- Multi-tenant Considerations:
- Isolation Guarantees: Ensuring separation between different customer environments
- Tenant Identification: Clear mechanisms for identifying specific tenants
- Cross-tenant Prevention: Strong safeguards against unauthorized cross-tenant access
- Hierarchy Support: Handling of organizational hierarchies when relevant
- Audit and Compliance:
- Authentication Logging: Comprehensive records of authentication events
- Access Tracking: Monitoring of resource access patterns
- Compliance Support: Features supporting regulatory requirements
- Anomaly Detection: Identification of unusual access patterns
These authentication mechanisms provide the security foundation necessary for enterprise integration, ensuring that Grok access is properly controlled, monitored, and protected according to organizational requirements.
Integration Code Examples
While official integration examples may vary, these representative code samples illustrate typical integration patterns:
Python Integration Example:
import requests
import json
# Configuration
API_KEY = "your_api_key_here"
API_ENDPOINT = "https://api.xai.com/v1/conversation"
def query_grok(user_message, conversation_history=None):
"""
Send a query to Grok AI and return the response.
Args:
user_message (str): The user's message
conversation_history (list, optional): Previous conversation messages
Returns:
dict: The Grok response
"""
# Initialize messages with history or empty list
messages = conversation_history or []
# Add the new user message
messages.append({"role": "user", "content": user_message})
# Prepare the request payload
payload = {
"model": "grok-1.5",
"messages": messages,
"max_tokens": 1000,
"temperature": 0.7,
"web_access": True
}
# Set up headers with authentication
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# Make the API request
response = requests.post(
API_ENDPOINT,
headers=headers,
data=json.dumps(payload)
)
# Handle potential errors
if response.status_code != 200:
error_info = response.json() if response.text else {"error": "Unknown error"}
raise Exception(f"API request failed: {response.status_code} - {error_info}")
# Parse and return the response
result = response.json()
# Add the assistant response to the conversation history
if conversation_history is not None:
conversation_history.append(result["message"])
return result
# Example usage
conversation = []
# First query
response = query_grok("What are the latest developments in quantum computing?", conversation)
print(f"Grok: {response['message']['content']}")
# Follow-up query using the same conversation
response = query_grok("How might these developments affect cryptography?", conversation)
print(f"Grok: {response['message']['content']}")
JavaScript/Node.js Integration Example:
const axios = require('axios');
// Configuration
const API_KEY = 'your_api_key_here';
const API_ENDPOINT = 'https://api.xai.com/v1/conversation';
/**
* Send a query to Grok AI and return the response.
*
* @param {string} userMessage - The user's message
* @param {Array} conversationHistory - Previous conversation messages (optional)
* @returns {Promise<Object>} - The Grok response
*/
async function queryGrok(userMessage, conversationHistory = []) {
// Initialize messages with history or empty array
const messages = [...conversationHistory];
// Add the new user message
messages.push({ role: 'user', content: userMessage });
// Prepare the request payload
const payload = {
model: 'grok-1.5',
messages: messages,
max_tokens: 1000,
temperature: 0.7,
web_access: true
};
// Set up headers with authentication
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`
};
try {
// Make the API request
const response = await axios.post(API_ENDPOINT, payload, { headers });
// Extract the result
const result = response.data;
// Add the assistant response to the conversation history
conversationHistory.push(result.message);
return result;
} catch (error) {
// Handle errors
const errorInfo = error.response?.data || { error: 'Unknown error' };
throw new Error(`API request failed: ${error.response?.status || 'Unknown'} - ${JSON.stringify(errorInfo)}`);
}
}
// Example usage with async/await
async function demonstrateGrokConversation() {
const conversation = [];
try {
// First query
const response1 = await queryGrok('What are the latest developments in quantum computing?', conversation);
console.log(`Grok: ${response1.message.content}`);
// Follow-up query using the same conversation
const response2 = await queryGrok('How might these developments affect cryptography?', conversation);
console.log(`Grok: ${response2.message.content}`);
} catch (error) {
console.error('Error:', error.message);
}
}
demonstrateGrokConversation();
Enterprise Integration Example (Hypothetical):
import { GrokAIClient, ConversationOptions } from '@xai/grok-client';
import { Logger } from './logger';
import { CacheService } from './cache-service';
import { SecurityService } from './security-service';
class EnterpriseGrokIntegration {
private client: GrokAIClient;
private logger: Logger;
private cache: CacheService;
private security: SecurityService;
constructor(
apiKey: string,
endpoint: string = 'https://api.xai.com/v1',
organizationId: string = null
) {
// Initialize the client with enterprise configuration
this.client = new GrokAIClient({
apiKey,
baseURL: endpoint,
organizationId,
timeout: 30000,
retries: 3
});
// Initialize supporting services
this.logger = new Logger('GrokAI');
this.cache = new CacheService();
this.security = new SecurityService();
}
/**
* Process a user query with appropriate security and caching
*/
async processQuery(
userId: string,
userMessage: string,
conversationId: string = null,
options: ConversationOptions = {}
) {
// Log the incoming request
this.logger.info('Processing query', { userId, conversationId });
// Check authorization
await this.security.validateAccess(userId, 'grok:query');
// Check cache for identical recent queries
const cacheKey = this.generateCacheKey(userMessage, options);
const cachedResponse = await this.cache.get(cacheKey);
if (cachedResponse && this.isCacheValid(cachedResponse, options)) {
this.logger.info('Cache hit', { cacheKey });
return cachedResponse.data;
}
try {
// Retrieve conversation history if conversationId provided
let conversation = conversationId
? await this.getConversationHistory(conversationId)
: [];
// Process any sensitive information in the message
const processedMessage = await this.security.sanitizeContent(userMessage);
// Make the API call
const response = await this.client.createCompletion({
messages: [...conversation, { role: 'user', content: processedMessage }],
model: options.model || 'grok-1.5',
max_tokens: options.maxTokens || 1000,
temperature: options.temperature || 0.7,
web_access: options.webAccess || false,
stream: options.stream || false
});
// Store in cache if appropriate
if (options.cache !== false) {
await this.cache.set(cacheKey, {
data: response,
timestamp: Date.now(),
ttl: options.cacheTTL || 3600
});
}
// Store conversation if tracking
if (conversationId) {
await this.storeConversationMessage(
conversationId,
{ role: 'user', content: processedMessage }
);
await this.storeConversationMessage(
conversationId,
response.message
);
}
// Log the successful response
this.logger.info('Query processed successfully', {
userId,
conversationId,
tokens: response.usage.total_tokens
});
return response;
} catch (error) {
// Log the error
this.logger.error('Error processing query', {
userId,
conversationId,
error: error.message
});
// Rethrow or handle as appropriate
throw error;
}
}
// Additional methods for conversation management, caching, etc.
private async getConversationHistory(conversationId: string) { /* ... */ }
private async storeConversationMessage(conversationId: string, message: any) { /* ... */ }
private generateCacheKey(message: string, options: any) { /* ... */ }
private isCacheValid(cachedItem: any, options: any) { /* ... */ }
}
These code examples illustrate typical integration patterns ranging from simple direct API interaction to more sophisticated enterprise implementations with security, logging, and caching considerations.
Performance Optimization Strategies
Maximizing the effectiveness of Grok AI implementations requires strategic approaches to optimization across multiple dimensions.
Query Optimization
The formulation and processing of queries significantly impacts both performance and response quality:
- Query Formulation Best Practices:
- Clarity and Specificity: Clear, direct queries typically yield better results with less processing
- Context Efficiency: Providing necessary context while avoiding unnecessary detail
- Instruction Structure: Using explicit, well-structured instructions for complex requests
- Query Decomposition: Breaking complex queries into logical components when appropriate
- Input Processing Optimization:
- Pre-processing Techniques: Normalizing inputs before submission
- Context Window Management: Strategic approaches to utilizing limited context space
- Batch Processing: Combining related queries when appropriate for efficiency
- Query Classification: Routing different query types through optimized processing paths
- Prompt Engineering Strategies:
- Template Development: Creating effective templates for common query types
- Instruction Refinement: Iterative improvement of instructions for optimal results
- Format Specification: Clearly indicating desired response formats
- Example Inclusion: Providing examples for complex or unusual requests
- Web Access Optimization:
- Access Triggering: Fine-tuning when web browsing capability is activated
- Query Formulation: Optimizing how natural language queries translate to search queries
- Source Selection: Enhancing the identification of high-value information sources
- Information Extraction: Improving the extraction of relevant content from accessed pages
These query optimization strategies can significantly enhance both the efficiency and effectiveness of Grok interactions, particularly for complex or specialized use cases.
Response Tuning
Several approaches can enhance the quality, relevance, and usefulness of Grok's responses:
- Generation Parameter Optimization:
- Temperature Calibration: Finding optimal temperature settings for different response types
- Top-p/Top-k Tuning: Refining sampling constraints for improved output quality
- Length Management: Calibrating max_tokens settings to balance detail with conciseness
- Frequency/Presence Penalties: Fine-tuning repetition avoidance parameters
- Response Formatting Strategies:
- Structure Specification: Explicitly requesting desired organizational structures
- Format Templates: Developing effective templates for common response types
- Consistency Patterns: Establishing conventions for predictable formatting
- Adaptive Formatting: Dynamically adjusting formats based on content type and complexity
- Content Enhancement Techniques:
- Post-processing Refinement: Applying specific transformations to raw responses
- Synthetic Example Generation: Creating illustrative examples for complex concepts
- Citation Enhancement: Improving attribution for externally sourced information
- Visualization Preparation: Formatting responses for effective visualization
- Multi-turn Optimization:
- Follow-up Strategy: Developing effective patterns for refining initial responses
- Clarification Protocols: Establishing efficient approaches for resolving ambiguities
- Conversation Management: Maintaining coherence across extended interactions
- Progressive Disclosure: Delivering information in logical, digestible sequences
These response tuning approaches can substantially improve the user experience by ensuring outputs are relevant, well-structured, and appropriately detailed for specific use cases.
System Configuration
Optimal system configuration significantly impacts Grok's performance, reliability, and efficiency:
- Deployment Architecture Optimization:
- Server Configuration: Optimizing host system settings for inference workloads
- Load Balancing: Implementing effective request distribution algorithms
- Scaling Triggers: Defining appropriate thresholds for capacity expansion
- Redundancy Design: Creating appropriate failover and high-availability configurations
- Resource Allocation Strategies:
- GPU Memory Management: Optimizing memory allocation for efficient inference
- Batch Size Optimization: Finding optimal batch sizes for different query types
- Concurrency Control: Managing parallel request processing effectively
- Resource Reservation: Appropriate allocation of resources for critical workloads
- Caching Implementation:
- Response Caching: Storing and reusing responses for common queries
- Embedding Caching: Preserving computed embeddings when appropriate
- Token Cache Optimization: Fine-tuning key-value cache management
- Cache Invalidation: Implementing appropriate freshness controls
- Network Optimization:
- Connection Pooling: Maintaining efficient connection management
- Compression Strategies: Implementing appropriate data compression
- Request Batching: Combining related requests when appropriate
- Timeout Management: Configuring appropriate timeouts for different operations
These system configuration optimizations can significantly improve overall performance, particularly at scale, enabling more efficient resource utilization and enhanced user experience.
Technical Limitations
Understanding the boundaries of optimization helps establish realistic expectations and appropriate implementation approaches:
- Fundamental Model Constraints:
- Context Window Limits: Fixed maximum context size limiting information retention
- Reasoning Depth Boundaries: Inherent limitations in complex reasoning capabilities
- Knowledge Cutoff Constraints: Limitations in pre-trained knowledge despite web access
- Inference Speed Physics: Hardware-imposed limits on processing speed
- Optimization Diminishing Returns:
- Hardware Scaling Plateaus: Points where additional hardware provides minimal improvement
- Parameter Tuning Limits: Boundaries beyond which parameter adjustments yield minimal gains
- Prompt Engineering Ceilings: Inherent limits to what prompt refinement can achieve
- Architecture Optimization Boundaries: Fundamental limits of architectural improvements
- Integration Constraints:
- API Rate Limitations: Throughput constraints imposed by API rate limits
- Latency Irreducibility: Minimum achievable latency given physical constraints
- Streaming Limitations: Constraints in streaming response mechanisms
- Concurrency Boundaries: Limits to effective parallel processing
- Feature-specific Limitations:
- Web Access Constraints: Limitations in real-time information retrieval
- Multi-turn Interaction Boundaries: Constraints in extended conversation management
- Domain Specialization Limits: Boundaries of performance in specialized domains
- Multimodal Processing Constraints: Limitations in image understanding capabilities
Recognizing these technical limitations informs realistic implementation planning, helping organizations develop appropriate strategies that work within Grok's capabilities rather than attempting optimizations beyond fundamental constraints.
Expert Recommendations
Based on my experience implementing AI solutions across different organizational contexts, I recommend several strategic approaches to Grok optimization:
- Strategic Implementation Guidance:
- Start with Bounded Use Cases: Begin with clearly defined, limited-scope implementations before expanding
- Establish Clear Success Metrics: Define specific, measurable criteria for evaluating effectiveness
- Implement Tiered Support Model: Develop escalation paths from AI to human assistance when appropriate
- Adopt Hybrid AI/Human Workflows: Design processes that leverage the complementary strengths of both
- Performance Optimization Priorities:
- Focus on Query Quality First: Invest in prompt engineering before hardware scaling
- Implement Strategic Caching: Develop intelligent caching for common queries
- Optimize Context Usage: Develop standards for efficient context window utilization
- Balance Latency and Throughput: Consider both response time and overall capacity in optimization
- Integration Architecture Recommendations:
- Design for Resilience: Implement fault-tolerant patterns that handle API unavailability
- Develop Abstraction Layers: Create middleware that simplifies interaction and enables future flexibility
- Implement Intelligent Routing: Direct different query types to appropriate processing paths
- Establish Monitoring Frameworks: Deploy comprehensive performance and quality monitoring
- Operational Best Practices:
- Continuous Prompt Refinement: Iteratively improve prompts based on performance data
- Regular Performance Benchmarking: Establish baseline measurements and track changes over time
- User Experience Monitoring: Collect feedback on AI interaction quality beyond technical metrics
- Capability Education: Invest in helping users understand how to effectively interact with the system
These expert recommendations reflect practical wisdom gained from implementing AI solutions at scale, focusing on approaches that deliver tangible value while working within the realistic capabilities and constraints of current technology.
Security and Technical Risk Assessment
Implementing Grok AI in enterprise environments requires comprehensive understanding of security considerations and appropriate risk management approaches.
Security Architecture Analysis
Grok's security architecture encompasses multiple layers of protection designed to ensure confidentiality, integrity, and availability:
- Data Protection Architecture:
- Transport Security: TLS 1.3 encryption for all API communications
- Storage Security: Encrypted storage for conversation history and user data
- Memory Protection: Secure memory handling for sensitive information
- Key Management: Sophisticated systems for managing authentication credentials
- Access Control Framework:
- Authentication Systems: Multi-layered authentication for API access
- Authorization Controls: Granular permission management for different capabilities
- Rate Limiting: Protection against excessive usage and potential abuse
- IP Restrictions: Optional controls for limiting access to specific network ranges
- Processing Security:
- Input Validation: Comprehensive validation of all user inputs
- Query Isolation: Separation between different users' queries and contexts
- Execution Boundaries: Strong isolation for code execution and similar capabilities
- Output Filtering: Security reviews of generated content before delivery
- Web Access Security:
- Query Sanitization: Removal of potentially harmful elements from search queries
- Content Isolation: Secure handling of accessed web content
- Source Validation: Verification of accessed information sources
- Access Logging: Comprehensive recording of external information access
- Infrastructure Security:
- Network Segmentation: Logical separation of different system components
- Defense in Depth: Multiple security layers protecting critical assets
- Monitoring Systems: Real-time security event monitoring and alerting
- Regular Assessments: Ongoing security testing and evaluation
This multi-layered security architecture provides foundational protection, though specific implementations may vary based on deployment model and organizational requirements.
Vulnerability Assessment
Understanding potential vulnerabilities is essential for developing appropriate security controls and risk management strategies:
- API Security Considerations:
- Authentication Bypass Risks: Potential vulnerabilities in authentication mechanisms
- Authorization Flaws: Possible weaknesses in permission enforcement
- Input Validation Gaps: Potential for malformed inputs to cause unexpected behavior
- Information Disclosure Vectors: Possible unintended information leakage in responses
- Model-specific Vulnerabilities:
- Prompt Injection Risks: Potential for carefully crafted inputs to manipulate model behavior
- Training Data Extraction: Techniques attempting to extract training data fragments
- Jailbreaking Attempts: Methods designed to circumvent safety constraints
- Adversarial Inputs: Specially crafted inputs designed to produce harmful outputs
- Integration Vulnerabilities:
- Credential Management Risks: Insecure handling of API keys or authentication tokens
- Insecure Data Transmission: Potential weaknesses in data protection during transit
- Third-party Dependencies: Security risks from supporting libraries or services
- Implementation Flaws: Vulnerabilities introduced during custom integration development
- Operational Security Concerns:
- Configuration Weaknesses: Security issues resulting from suboptimal settings
- Logging Inadequacies: Insufficient audit trails for security-relevant events
- Incident Response Gaps: Weaknesses in detecting or responding to security incidents
- Update Management Issues: Potential vulnerabilities from delayed security updates
Understanding these potential vulnerability categories enables organizations to implement appropriate controls and monitoring to address specific risks in their Grok implementations.
Mitigation Techniques
Several effective approaches can address identified security risks and vulnerabilities:
- Authentication and Authorization Controls:
- Multi-factor Authentication: Requiring multiple verification factors for sensitive operations
- Principle of Least Privilege: Granting only necessary permissions to each system component
- Regular Credential Rotation: Periodically changing authentication credentials
- OAuth Implementation: Using established authorization frameworks for secure delegation
- Input/Output Security:
- Request Validation: Comprehensive validation of all API requests
- Prompt Safety Preprocessing: Scanning and filtering potentially malicious inputs
- Output Content Filtering: Reviewing generated content for security issues
- Rate Limiting Implementation: Preventing abuse through request volume controls
- Data Protection Measures:
- End-to-end Encryption: Protecting data throughout its lifecycle
- Minimal Data Collection: Gathering only necessary information
- Data Retention Controls: Appropriate policies for information storage duration
- Secure Deletion Practices: Proper removal of sensitive information when no longer needed
- Operational Security Practices:
- Regular Security Assessments: Ongoing evaluation of security posture
- Vulnerability Monitoring: Tracking emerging threats and vulnerabilities
- Security Logging: Comprehensive recording of security-relevant events
- Incident Response Planning: Preparation for potential security incidents
- Integration Security Enhancement:
- Secure Development Practices: Following security best practices during integration development
- Dependency Management: Controlling and monitoring third-party components
- Code Review Processes: Security-focused examination of integration code
- Security Testing: Regular evaluation of integration security
These mitigation techniques provide a foundation for addressing security risks in Grok implementations, though specific approaches should be tailored to organizational requirements and risk profiles.
Security Testing Framework
Comprehensive security validation requires a structured testing approach across multiple dimensions:
- Penetration Testing Methodology:
- API Security Testing: Evaluating authentication, authorization, and input validation
- Model Interaction Testing: Attempting to circumvent safety mechanisms
- Infrastructure Assessment: Examining deployment environment security
- Integration Validation: Testing security of custom integration components
- Functional Security Validation:
- Safety Boundary Testing: Verifying effectiveness of content safety controls
- Authentication Verification: Confirming proper implementation of access controls
- Permission Enforcement Testing: Validating authorization boundaries
- Error Handling Assessment: Evaluating security of error response mechanisms
- Compliance Validation:
- Regulatory Requirement Testing: Verifying adherence to applicable regulations
- Policy Compliance Checks: Confirming alignment with organizational security policies
- Industry Standard Validation: Assessing against relevant security frameworks
- Documentation Review: Examining security-related documentation completeness
- Operational Security Verification:
- Logging Effectiveness: Confirming appropriate event recording
- Monitoring Configuration: Validating security event detection
- Incident Response Testing: Simulating security incidents to evaluate response
- Backup and Recovery Validation: Testing data protection and restoration capabilities
- Continuous Security Validation:
- Automated Security Scanning: Regular automated security assessment
- Vulnerability Management: Tracking and addressing identified issues
- Security Update Verification: Confirming proper implementation of security patches
- Configuration Drift Detection: Identifying unauthorized security setting changes
This security testing framework provides a comprehensive approach to validating Grok implementations, enabling organizations to identify and address potential security issues before they can be exploited.
Expert Recommendations: Cybersecurity Perspective
Drawing from my experience in cybersecurity and AI implementation, I recommend several strategic approaches to securing Grok deployments:
- Security-by-Design Implementation:
- Security Requirements Definition: Establish clear security requirements before implementation
- Architecture Review: Conduct security-focused evaluation of proposed integration architecture
- Secure Development Practices: Implement security throughout the development lifecycle
- Pre-deployment Security Assessment: Comprehensive security testing before production deployment
- Data Governance Strategy:
- Information Classification: Clearly categorize data for appropriate handling
- Processing Boundaries: Establish clear limits on what data can be processed with Grok
- Retention Controls: Implement appropriate policies for conversation and query storage
- Privacy-centric Design: Minimize unnecessary data collection and retention
- Access Management Framework:
- Identity Integration: Connect with existing organizational identity systems
- Role-based Access: Implement appropriately granular permission models
- Session Management: Develop secure approaches to managing user sessions
- Access Monitoring: Implement comprehensive tracking of system access
- Operational Security Approach:
- Security Monitoring Integration: Connect with organizational security monitoring
- Incident Response Procedures: Develop specific plans for AI-related security incidents
- Regular Security Review: Conduct periodic reassessment of security posture
- Security Awareness Training: Educate users about safe interaction practices
- Risk-appropriate Implementation:
- Use Case Risk Assessment: Evaluate security requirements based on specific applications
- Tiered Security Model: Implement controls proportional to use case sensitivity
- Progressive Implementation: Begin with lower-risk applications before expanding
- Continuous Risk Evaluation: Regularly reassess risk profile as usage evolves
These recommendations provide a strategic foundation for secure Grok implementation, focusing on practical approaches that balance security requirements with operational needs while addressing the specific risk characteristics of AI systems.
Future Technical Developments
Understanding the likely trajectory of Grok AI's technical evolution helps organizations prepare strategically for upcoming capabilities and improvements.
Architecture Evolution
Several architectural advancements are likely to shape Grok's future development:
- Model Architecture Enhancements:
- Mixture of Experts (MoE) Integration: Potential adoption of sparse activation approaches for increased parameter efficiency
- Attention Mechanism Refinement: Further optimization of attention computation for improved efficiency and capability
- Context Window Expansion: Progressive increases in context capacity beyond current limitations
- Modular Architecture Development: Potential shift toward more specialized components for different tasks
- Multimodal Advancement:
- Enhanced Visual Understanding: Improved image processing capabilities beyond Grok-1.5V's initial implementation
- Additional Modality Support: Potential expansion to audio, video, and other data types
- Cross-modal Reasoning: More sophisticated integration of information across different modalities
- Unified Representation Space: Enhanced alignment between different data type representations
- Memory Architecture Improvements:
- External Memory Integration: Potential development of persistent memory systems beyond the context window
- Hierarchical Memory Structures: More sophisticated organization of information across different timeframes
- Retrieval Augmentation Refinement: Enhanced techniques for accessing and utilizing external knowledge
- Long-term Context Management: Better handling of extensive conversation history
- Reasoning Framework Evolution:
- Structured Reasoning Components: More explicit architecture for multi-step reasoning
- Tool Use Integration: Enhanced capabilities for leveraging external tools and functions
- Verification Mechanisms: Built-in approaches for validating reasoning steps
- Planning Capabilities: More sophisticated approaches to developing and executing plans
These architectural evolutions would significantly enhance Grok's capabilities while potentially improving efficiency and addressing current limitations in areas like context management and reasoning complexity.
Performance Trajectory
Grok's performance is likely to advance along several important dimensions:
- Capability Improvement Areas:
- Reasoning Enhancement: Continued focus on improving complex problem-solving abilities
- Knowledge Integration: Better synthesis of information from diverse sources
- Instruction Following: Enhanced ability to follow complex, multi-step instructions
- Domain-specific Expertise: Improved performance in specialized areas like coding, mathematics, and creative tasks
- Efficiency Advancements:
- Computational Efficiency: Reduced resource requirements through architectural and algorithmic improvements
- Latency Reduction: Faster response generation, particularly for complex queries
- Throughput Enhancement: Increased processing capacity for multi-user environments
- Resource Utilization Optimization: More efficient use of memory and processing resources
- Reliability Improvements:
- Hallucination Reduction: Continued progress in minimizing factual inaccuracies
- Consistency Enhancement: Greater reliability in extended reasoning chains
- Error Recovery: Better handling of misunderstandings and ambiguities
- Edge Case Management: Improved performance in unusual or boundary scenarios
- Benchmark Progression:
- Standard Benchmark Advancement: Continued improvement on established evaluation metrics
- New Benchmark Development: Creation of more sophisticated evaluation approaches
- Real-world Performance Focus: Greater emphasis on practical application benchmarks
- User Experience Metrics: Development of more holistic evaluation frameworks
These performance trajectories suggest significant ongoing improvement in Grok's capabilities, with particular emphasis on reasoning reliability, efficiency, and specialized expertise development.
Integration Roadmap
The evolution of Grok's integration capabilities will likely include several important developments:
- API Enhancement:
- Expanded Endpoint Functionality: New capabilities through additional API endpoints
- Fine-grained Control: More detailed parameter options for response customization
- Function Calling Expansion: Enhanced capabilities for tool use and function execution
- Streaming Improvement: More sophisticated real-time response delivery
- Enterprise Integration Development:
- Enhanced Administration Tools: More comprehensive management capabilities
- Advanced Security Features: Additional enterprise-grade security controls
- Compliance Certification: Formal validation against industry standards
- Custom Deployment Options: More flexible implementation approaches
- Ecosystem Expansion:
- SDKs and Libraries: Comprehensive development kits for multiple languages
- Integration Templates: Pre-built patterns for common implementation scenarios
- Partner Integrations: Ready-made connections with popular enterprise systems
- Developer Community: Expanded resources for implementation support
- Knowledge Integration Capabilities:
- Custom Knowledge Base Connection: Ability to incorporate organization-specific information
- Retrieval Enhancement: More sophisticated information access mechanisms
- Training Data Customization: Potential for organization-specific model adaptation
- Specialized Vertical Solutions: Industry-specific integration approaches
These integration roadmap elements would significantly enhance Grok's utility in enterprise environments, enabling more sophisticated and customized implementations across various use cases and industries.
Technical Challenges
Several significant challenges are likely to shape Grok's technical development trajectory:
- Fundamental Research Challenges:
- Reasoning Depth Limitations: Addressing constraints in complex multi-step reasoning
- Abstraction Challenges: Improving handling of highly abstract concepts
- World Model Fidelity: Enhancing underlying representations of physical and social reality
- Causality Understanding: Developing better models of cause and effect relationships
- Practical Implementation Challenges:
- Resource Efficiency Demands: Need for continued improvement in computational efficiency
- Latency Expectations: Meeting requirements for increasingly responsive interactions
- Scale Requirements: Supporting growing implementation size and complexity
- Integration Complexity: Addressing challenges in connecting with diverse systems
- Safety and Alignment Challenges:
- Evolving Abuse Vectors: Responding to new techniques for circumventing safeguards
- Value Alignment Complexity: Navigating diverse perspectives on appropriate behaviors
- Transparency Requirements: Meeting growing demands for explainability
- Emergent Behavior Management: Addressing unexpected capabilities or limitations
- Knowledge Management Challenges:
- Information Currency: Maintaining awareness of rapidly changing information
- Knowledge Verification: Validating the accuracy of incorporated information
- Specialized Domain Depth: Developing sufficiently deep expertise in technical areas
- Conflicting Information Resolution: Effectively handling contradictory sources
Addressing these technical challenges will require significant research and development effort, with progress likely to be evolutionary rather than revolutionary, gradually enhancing capabilities while managing associated risks.
Research Directions
Several active research areas are likely to influence Grok's future development:
- Fundamental AI Research Areas:
- Advanced Reasoning Architectures: New approaches to multi-step logical reasoning
- Retrieval Augmented Generation (RAG): Enhanced techniques for leveraging external knowledge
- Multimodal Integration: More sophisticated alignment between different data types
- Efficient Training Methods: Approaches requiring less computation for capability development
- Applied Research Directions:
- Tool Use Framework: More sophisticated approaches to leveraging external tools
- Planning Systems: Enhanced capabilities for developing and executing complex plans
- Agent Architectures: Evolution toward more agent-like behavior and autonomy
- Interactive Learning: Approaches for improving through user interaction
- Technical Optimization Research:
- Model Compression Techniques: Methods for reducing model size while preserving capabilities
- Inference Optimization: New approaches to more efficient response generation
- Quantization Advancement: Improved low-precision computation methods
- Hardware Specialization: Custom computing approaches for language model workloads
- Safety Research Priorities:
- Alignment Techniques: Methods for ensuring model behavior matches human values
- Evaluation Frameworks: More comprehensive approaches to safety assessment
- Interpretability Methods: Techniques for understanding internal model behavior
- Adversarial Defense: Approaches for preventing manipulation or misuse
These research directions represent active areas of investigation that will likely influence Grok's evolution, though the specific implementation of research advances will depend on xAI's strategic priorities and technical approach.
Technical Resources
Documentation Links
While comprehensive official documentation for Grok AI continues to evolve, several resources provide valuable technical information:
- Official Documentation Resources:
- xAI Developer Portal - Primary source for official documentation
- Grok API Reference - Detailed API specifications and usage guidelines
- Grok Integration Guide - Implementation best practices and examples
- X Premium+ Documentation - Information on accessing Grok through X
- Technical Guides and Tutorials:
- Getting Started with Grok AI - Introductory implementation guide
- Prompt Engineering Guide - Best practices for effective prompting
- Web Access Implementation - Guide to leveraging real-time information
- Advanced Integration Patterns - Sophisticated implementation approaches
- Reference Documentation:
- API Endpoint Reference - Comprehensive endpoint specifications
- Parameter Documentation - Detailed parameter descriptions and usage
- Error Code Reference - Common error codes and resolution approaches
- SDK Documentation - Guidelines for language-specific development kits
- Resources for Specific Use Cases:
- Enterprise Implementation Guide - Best practices for organizational deployment
- Security Best Practices - Security guidelines and recommendations
- Performance Optimization Guide - Techniques for maximizing effectiveness
- Integration Examples - Sample code for common implementation scenarios
Research Papers
While xAI has not published comprehensive research papers on Grok's architecture, several relevant academic resources provide context for understanding the technologies underlying models like Grok:
- Foundational Research:
- Vaswani, A., et al. (2017). "Attention Is All You Need." Neural Information Processing Systems (NIPS 2017). - Introduces the transformer architecture that forms the foundation of modern LLMs.
- Brown, T. B., et al. (2020). "Language Models are Few-Shot Learners." Neural Information Processing Systems (NeurIPS 2020). - Describes scaling laws and capabilities that inform models like Grok.
- Ouyang, L., et al. (2022). "Training Language Models to Follow Instructions with Human Feedback." arXiv preprint arXiv:2203.02155. - Details RLHF techniques likely used in Grok's development.
- Technical Capabilities Research:
- Wei, J., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." Neural Information Processing Systems (NeurIPS 2022). - Explores reasoning capabilities relevant to Grok's development.
- Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Neural Information Processing Systems (NeurIPS 2020). - Describes techniques related to Grok's real-time information access.
- Shazeer, N., et al. (2017). "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer." International Conference on Learning Representations (ICLR 2017). - Introduces MoE architectures that may influence future Grok versions.
- Optimization and Efficiency Research:
- Dettmers, T., et al. (2022). "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale." Neural Information Processing Systems (NeurIPS 2022). - Explores quantization techniques relevant to inference efficiency.
- Su, J., et al. (2021). "FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness." Neural Information Processing Systems (NeurIPS 2022). - Describes attention optimization techniques likely relevant to Grok.
- Anil, R., et al. (2023). "Palm 2 Technical Report." arXiv preprint arXiv:2305.10403. - Provides insights into contemporary model development approaches.
- Safety and Alignment Research:
- Bai, Y., et al. (2022). "Constitutional AI: Harmlessness from AI Feedback." arXiv preprint arXiv:2212.08073. - Describes advanced alignment techniques relevant to modern LLMs.
- Korbak, T., et al. (2023). "Pretraining Language Models with Human Preferences." International Conference on Machine Learning (ICML 2023). - Explores alignment approaches during pre-training.
- Ganguli, D., et al. (2022). "Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned." arXiv preprint arXiv:2209.07858. - Discusses safety evaluation techniques likely used during Grok's development.
Developer Communities
Several communities and forums provide valuable resources for Grok implementation and discussion:
- Official Developer Communities:
- xAI Developer Forum - Official discussion space for implementation questions
- X Developer Community - Broader X platform developer discussions including Grok integration
- Independent Technical Communities:
These communities provide valuable spaces for knowledge sharing, problem-solving, and staying current with evolving best practices around Grok and similar LLM implementations.
Downloadable Resource: Technical Integration Guide
To support your Grok AI implementation efforts, we've created a comprehensive technical integration guide that provides detailed guidance for successful deployment and integration.
Download Grok AI Technical Integration Guide (PDF)
This detailed resource includes:
1. Architecture and Implementation Planning
- Detailed architectural patterns for different deployment scenarios
- Decision frameworks for selecting optimal integration approaches
- Comprehensive planning templates for implementation projects
- Security and compliance considerations with implementation checklists
2. API Integration Deep Dive
- Complete API reference with detailed parameter documentation
- Authentication implementation with security best practices
- Error handling strategies with comprehensive troubleshooting guidance
- Performance optimization techniques for API usage
3. Advanced Implementation Patterns
- Enterprise integration architectures with detailed diagrams
- Caching strategies for performance enhancement
- High-availability deployment patterns
- Scaling approaches for growing implementation needs
4. Code Examples and Templates
- Production-ready implementation examples in multiple languages
- Security-focused code patterns with best practices
- Monitoring and logging implementation examples
- Error handling and resilience patterns
5. Performance Optimization Techniques
- Query optimization strategies with practical examples
- Response tuning approaches for different use cases
- System configuration guidelines for optimal performance
- Caching implementation examples with code samples
This comprehensive guide provides the detailed technical information needed to successfully implement Grok in various organizational contexts, from simple integrations to complex enterprise deployments.
Expert Technical Implementation Support
Implementing Grok AI effectively requires both technical expertise and strategic planning. As a technology entrepreneur with extensive experience building AI-powered solutions in cybersecurity and digital identity, I can provide valuable guidance for your implementation journey.
Schedule a Technical Consultation to Discuss:
- Architecture design for your specific implementation requirements
- Security and compliance approaches tailored to your organizational needs
- Performance optimization strategies for your particular use cases
- Integration patterns for connecting with your existing systems
- Implementation roadmap development with practical milestones
Schedule a Technical Implementation Consultation →
Request a Technical Assessment
If you've already begun implementing Grok or are evaluating its potential for your organization, I can provide an expert assessment of your approach.
Technical Assessment Services Include:
- Architecture review with specific recommendations
- Security evaluation with risk mitigation strategies
- Performance analysis with optimization opportunities
- Integration approach assessment with enhancement suggestions
- Implementation roadmap review with prioritization guidance
Request a Technical Assessment →
My approach combines technical depth with practical implementation experience, focusing on solutions that deliver tangible business value while addressing the real-world challenges of AI implementation. I look forward to supporting your Grok implementation journey with expert guidance tailored to your specific needs.
Conclusion: The Technical Future of Grok AI
As we look toward the future of Grok AI, several key technical trends are likely to shape its evolution and impact:
Near-term Technical Evolution
The immediate technical trajectory for Grok AI will likely focus on refinement and enhancement rather than revolutionary change:
- Capability Enhancement: Continued improvement in reasoning abilities, factual accuracy, and specialized domain performance through iterative model refinement and training optimization.
- Multimodal Expansion: Further development of image understanding capabilities and potential expansion to additional modalities like audio, creating a more comprehensive interaction experience.
- Enterprise Feature Development: Growth of capabilities specifically designed for organizational implementation, including enhanced security features, administration tools, and integration options.
- Performance Optimization: Ongoing improvements in efficiency, latency, and resource utilization to enhance the user experience and reduce implementation costs.
These near-term developments represent natural extensions of Grok's current capabilities, providing incremental but meaningful improvements that enhance its utility across different use cases.
Longer-term Technical Possibilities
Looking further ahead, more substantial technical developments may reshape Grok's capabilities and implementation approaches:
- Architecture Transformation: Potential adoption of mixture-of-experts or similar architectures that dramatically improve parameter efficiency while enabling even greater model scale.
- Knowledge Integration Revolution: More sophisticated approaches to combining parametric knowledge with real-time information access, potentially including persistent memory systems that extend beyond the context window.
- Reasoning Framework Evolution: Development of more explicit reasoning architectures that enhance performance on complex problem-solving tasks requiring multi-step logical analysis.
- Tool Use Advancement: Enhanced capabilities for leveraging external tools and functions, potentially moving toward more agent-like behavior with greater autonomy in accomplishing complex tasks.
These longer-term possibilities represent more significant architectural and capability shifts that could substantially expand Grok's utility while addressing fundamental limitations of current LLM design.
Implementation Impact
These technical developments will have several important implications for organizations implementing Grok:
- Implementation Strategy Flexibility: Growing diversity of deployment options will enable more tailored implementations that match specific organizational needs and constraints.
- Use Case Expansion: Enhanced capabilities will open new application possibilities, extending Grok's utility beyond current domains into more specialized and complex use cases.
- Integration Ecosystem Maturation: Development of richer integration options, templates, and tools will simplify implementation and reduce technical barriers to adoption.
- Cost-Value Evolution: Ongoing efficiency improvements will likely improve the cost-effectiveness of Grok implementations, enhancing ROI for organizational deployments.
These implementation impacts suggest a gradual expansion of Grok's practical utility, with growing possibilities for organizational value creation through thoughtful deployment and integration.
Strategic Technical Considerations
Organizations considering or actively implementing Grok should keep several strategic technical considerations in mind:
- Capability-Strategy Alignment: Focus on matching Grok's evolving capabilities with genuine organizational needs rather than pursuing implementation for its own sake.
- Implementation Flexibility: Design integration approaches that can adapt to Grok's technical evolution without requiring complete redevelopment.
- Hybrid System Design: Develop systems that effectively combine AI capabilities with human expertise rather than seeking full automation of complex functions.
- Continuous Learning Approach: Establish processes for ongoing evaluation and refinement of implementations as capabilities and organizational needs evolve.
These strategic considerations emphasize the importance of thoughtful, adaptable implementation approaches that can evolve alongside Grok's technical capabilities while delivering sustained organizational value.
The technical future of Grok AI represents a journey of continuous enhancement and evolution rather than a destination. By understanding the likely trajectory of this evolution and implementing with appropriate flexibility, organizations can derive growing value from Grok while preparing to leverage new capabilities as they emerge. The most successful implementations will be those that effectively balance current capabilities with future possibilities, creating systems that deliver immediate value while positioning for ongoing enhancement as Grok's technical capabilities continue to advance.
- Hugging Face Forum - LLM Section - Broader LLM implementation discussions including Grok
- AI Engineering Subreddit - Community discussions on AI implementation including Grok
- Stack Overflow - AI Tags - Implementation questions with expert answers
- LangChain Discord - Community focused on LLM application development
- Enterprise Implementation Groups:
- AI Infrastructure Alliance - Organization focused on enterprise AI implementation
- OWASP AI Security Project - Security-focused AI implementation guidance
- MLOps Community - Best practices for operationalizing AI systems
- Enterprise AI Forum - Discussion focused on organizational AI deployment
- Special Interest Communities:
- Prompt Engineering Community - Focused on effective prompt development
- LLM Security Alliance - Dedicated to secure AI implementation
- AI Ethics Discussion Group - Addressing ethical implementation considerations
- RAG Implementation Forum - Specialized community for retrieval-augmented generation
- xAI GitHub Organization - Code repositories and technical examples
- Grok Discord Server - Real-time discussion and implementation support